Is Web Scraping Legal? What You Need to Know in 2026

Your company is likely one of the many who are missing out on opportunities every year because of lack of data. Why?
Because there’s a common misconception that web scraping isn’t legal.
Web scraping public data is legal in most jurisdictions when done correctly. Legal – with court precedents, established compliance frameworks, and boundaries that offer far more potential than most companies realize.
And sadly, while your team debates whether it's allowed, competitors who understand how to leverage data scraping are making better decisions with way more data.
In this guide, we'll explore the confusion around the legality of data scraping, talk about real court precedents, and give you the compliance framework that will allow open worlds of data for your organization.
This article provides general informational guidance, not legal advice, and reflects common legal interpretations rather than guarantees.
Is Web Scraping Legal?
Think about how you'd do competitive research manually.
Visit a competitor's website. Look at their pricing page. Write down the prices. Move to the next competitor. Repeat ten times. Put everything in a spreadsheet. Analyze the data.
Is that legal? Obviously, yes.
Now, let’s say you're a developer. You write some code that visits those same pricing pages, extracts the same publicly visible prices, saves them in a database, and runs the same analysis.
The data hasn't changed – it's still public. The action hasn't changed, you're still just reading information displayed for anyone to see. Only the method changed from manual to automated.
Yet every week, companies make strategic decisions based on radically incomplete data because someone thinks scraping is illegal.
So what does the misconception stem from?
The misconception of web scraping legality
Here's how data projects die:
❌ "We can't use that solution, web scraping is illegal."
❌ "Legal won't approve it, it goes against platform terms."
❌ "Our compliance team says it's too risky."
These objections are based on a misconception that conflates three entirely different things:
- What platforms want
- What platforms claim in their Terms of Service
- What the law actually prohibits
The misconception that web scraping is legal is based on flawed logic:
Facebook's API doesn't give us comprehensive data → So getting that data must be illegal → So we can't use vendors who collect it → So we'll stick with the limited data APIs provide.
The reality is that:
- Facebook's API limitations are business decisions to control data access and monetization.Publicly visible Facebook posts are public data – and federal courts have explicitly ruled that collecting public data doesn't violate the Computer Fraud and Abuse Act, even when platforms object.
- Laws like CFAA and GDPR govern how you collect data – without circumventing authentication, bypassing security measures, and with proper handling of personal information. They don't prohibit collecting data that's intentionally published for public viewing.
The misconception sounds like risk management. In practice, it's rejection of legitimate data sources based on restrictions that don't exist. You’re then left with incomplete data while competitors who understand the law work with complete information.
Part of this confusion also stems from misunderstanding what web scraping actually involves on a technical level. Let's clear that up. ⬇️
What Does “Web Scraping" Really Mean?
When you visit a website in your browser:
- Your browser sends an HTTP request to the site's server
- The server responds with HTML, CSS, and JavaScript
- Your browser renders it as a visual webpage
- You read it and maybe copy information you need
When a scraper visits that same website:
- Software sends an HTTP request to the site's server
- The server responds with the exact same HTML, CSS, and JavaScript
- The software parses it to extract specific data
- The data gets saved in a structured format
Web scraping is not hacking
❌ Hacking means:
- Breaking into systems you're not authorized to access
- Bypassing passwords or security measures
- Exploiting vulnerabilities to see private data
- Using stolen credentials
✅ Web scraping means:
- Requesting publicly accessible web pages
- Using the exact same mechanisms any browser uses
- Extracting data that anyone could see
- Automating a process that's perfectly legal to do manually
Think of it this way: reading a poster in a shop window isn't trespassing. Taking notes about what you read isn't theft. Automating that note-taking doesn't suddenly become criminal.
The Ninth Circuit Court made this exact point in hiQ v. LinkedIn (more on this below): "Simply reading or looking at data to which one has authorized access (or from which authorization is not required) does not constitute 'access without authorization.'"
Web scraping is foundational internet technology
Far from being a questionable workaround, web scraping is how the internet actually works.
Google's search engine crawls billions of web pages daily. That's web scraping at massive scale. It's what makes the internet searchable. Without it, you'd need to know the exact URL of every website you wanted to visit.
The Wayback Machine scrapes and archives over 866 billion web pages for historical preservation. This creates enormous public value by preserving internet history that would otherwise disappear.
Price comparison tools like Honey and CamelCamelCamel scrape e-commerce sites to track pricing history and find better deals, saving consumers billions annually.
RSS readers scrape content updates across thousands of websites so you can follow news and blogs efficiently without visiting each site individually.
Your use case – competitive intelligence, market research, understanding what people are saying on social media – works on the exact same principle.
How to Determine If Your Data Scraping is Legal
Web scraping isn't automatically illegal. But it's not automatically legal either. Three specific factors determine whether you're on solid ground or potentially crossing a line.
Three factors determine whether you're in safe territory or potentially crossing a line. ⬇️

Factor 1: What kind of data are you collecting?
Not all public data is created equal.
Straightforward factual business data is the safest zone. Product prices, business hours, company addresses, public reviews, availability status – information that's published for people to see and use. Facts themselves can't be copyrighted under US law (the "idea-expression dichotomy"). Collecting them is generally straightforward.
Personal data gets more complicated, especially if you're dealing with European regulations. Even publicly visible information about individuals (LinkedIn profiles, Instagram handles, public social media posts) triggers data protection obligations under GDPR. This doesn't mean you can't collect it. It means you need a documented legal basis (usually "legitimate interest") and proper safeguards. We'll explain what this means in a bit.
Copyrighted creative content requires thoughtful legal analysis. Copyright law protects creative expression, not facts. Understanding how this applies to different types of web scraping is essential for compliance.
Factual data collection remains straightforward: Product specifications, prices, features, availability, ratings, timestamps, and business information. Facts themselves aren't copyrightable under US law, which makes collecting purely factual information the lowest-risk category.
Creative content – posts, articles, reviews, images, videos – operates differently. Even when publicly accessible, these works have copyright protection. Large-scale collection of public content for analytical purposes does occur across industries – social listening platforms, market research firms, academic researchers, and search engines all collect copyrighted content at scale. However, the legal footing for these practices depends heavily on how the data is used, and courts continue to refine the boundaries.
The key legal question isn't whether content is copyrighted (it is), but whether your use is transformative rather than substitutive.
Transformative uses that courts have recognized include:
- Collecting posts across millions of sources for aggregate sentiment analysis
- Structuring public data for trend detection and market research
- Enabling monitoring, compliance, and risk detection purposes
- Supporting academic research and business intelligence
- Cross-platform aggregation for enterprise monitoring and research (e.g., brand safety, competitive intelligence, adverse event detection)
These uses transform content published for social engagement into analytical insights, serving a fundamentally different purpose than the original publication.
Substitutive uses that create higher risk:
- Republishing content in ways that replace visiting the original source
- Creating searchable databases that eliminate need for original platforms
- Commercial redistribution without genuine analytical transformation
- Consumer-facing products that republish social content for entertainment or engagement purposes, competing with the original platforms
Fair use provides the legal framework for transformative collection, though it's evaluated case-by-case based on: (1) purpose and character of use, (2) nature of the copyrighted work, (3) amount and substantiality used, and (4) effect on the market for the original. Courts weigh these factors differently depending on specific facts and jurisdiction.
Important limitations: Copyright analysis in this area continues to evolve. Different courts reach different conclusions about similar practices. What constitutes "transformative use" versus "substitutive use" can be disputed. Fair use is a defense evaluated case-by-case, not a guaranteed right.
Best practices for copyright compliance:
- Focus on business intelligence and research purposes that serve fundamentally different functions than the original platforms' social engagement purposes
- Maintain proper attribution and links to original sources
- Serve purposes distinct from the original publication (analysis vs. engagement)
- Document your transformative use rationale and compliance measures
- Consult intellectual property counsel about your specific use cases and jurisdictions
Factor 2: How are you collecting the data?
The way you collect data matters just as much as what you collect.
You need to respect technical boundaries
Websites use different mechanisms to control access to their data:
Authentication requirements indicate data is private, not public. If a website requires login to view information, that data isn't publicly accessible, and accessing it requires authorization from the site owner.
CAPTCHAs and IP blocking are active countermeasures that prevent automated access. The Computer Fraud and Abuse Act prohibits circumventing "technological access barriers." Attempting to bypass these protections may constitute unauthorized access.
When sites implement rate limits, they're setting their rules of engagement. Respecting those limits (staying within the specified request thresholds) shows you're following their technical guidelines, not circumventing them.
If data is viewable without login, it's public. Respecting rate limits and technical parameters keeps collection compliant. Bypassing authentication or active barriers crosses into unauthorized access.
Following basic web etiquette shows you're acting in good faith
The robots.txt standard has existed since 1994 as a way for websites to communicate crawling preferences. While violating it isn't automatically illegal in most jurisdictions, respecting it demonstrates good faith and responsible operation.
Don't hammer servers
Making hundreds of requests per second that bring down someone's website creates liability even if the underlying data is public. Reasonable rate limiting (1-2 seconds between requests minimum) shows you're not causing harm.
Use honest identification
Don't disguise your scraper as a regular browser. The Internet Engineering Task Force recommends clear User-Agent identification. Use something like: Mozilla/5.0 (compatible; YourCompanyBot/1.0; +https://yourcompany.com/bot)
The line between legal scraping and legal trouble often comes down to whether you're being respectful or aggressive.
Factor 3: Where are you and who are you collecting data about?
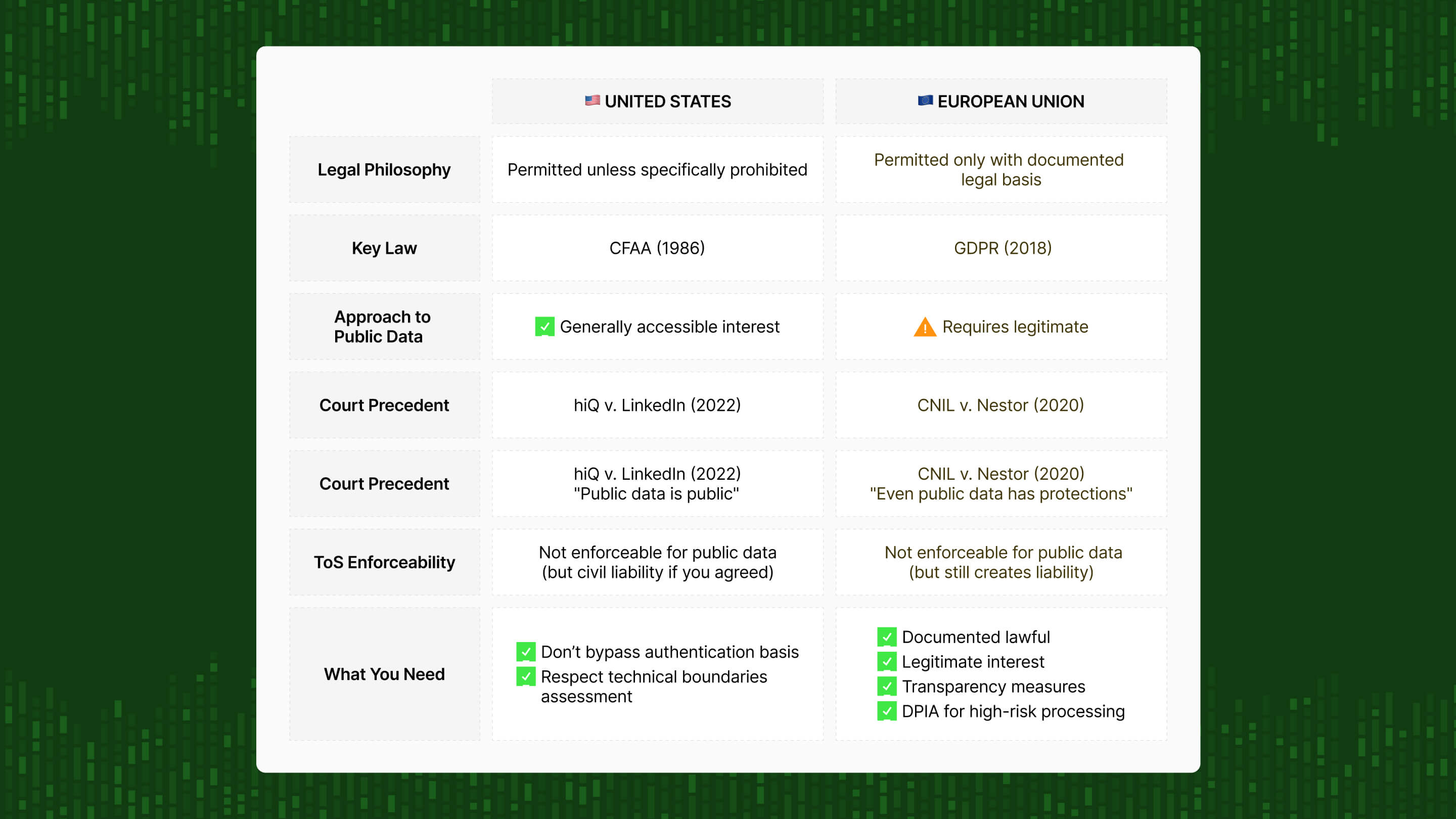
Geography fundamentally shapes what's legal because different regions have completely different legal philosophies.
The United States takes a relaxed approach: You can generally collect any public data unless there's a specific law prohibiting it. The Computer Fraud and Abuse Act restricts unauthorized access to protected systems, but recent court precedents have consistently ruled that accessing public data doesn't constitute "unauthorized access."
The European Union and UK are way more restrictive: GDPR requires a documented legal basis to process personal data, even if it's publicly visible. The regulation prioritizes individual privacy rights over business interests. You need legitimate interest assessments, transparency obligations, and safeguards we'll touch more on below.
The rest of the world is increasingly following the EU model. Canada's PIPEDA, Brazil's LGPD, California's CCPA/CPRA, Japan's APPI, and others have adopted GDPR-inspired frameworks emphasizing data protection.
If you're a global company, you typically need to comply with the strictest applicable regulation. Which usually means GDPR if there's any chance EU citizens' data is involved.
A simple test to determine if your data scraping is legal
Here's a practical framework that clarifies most web scraping questions immediately:
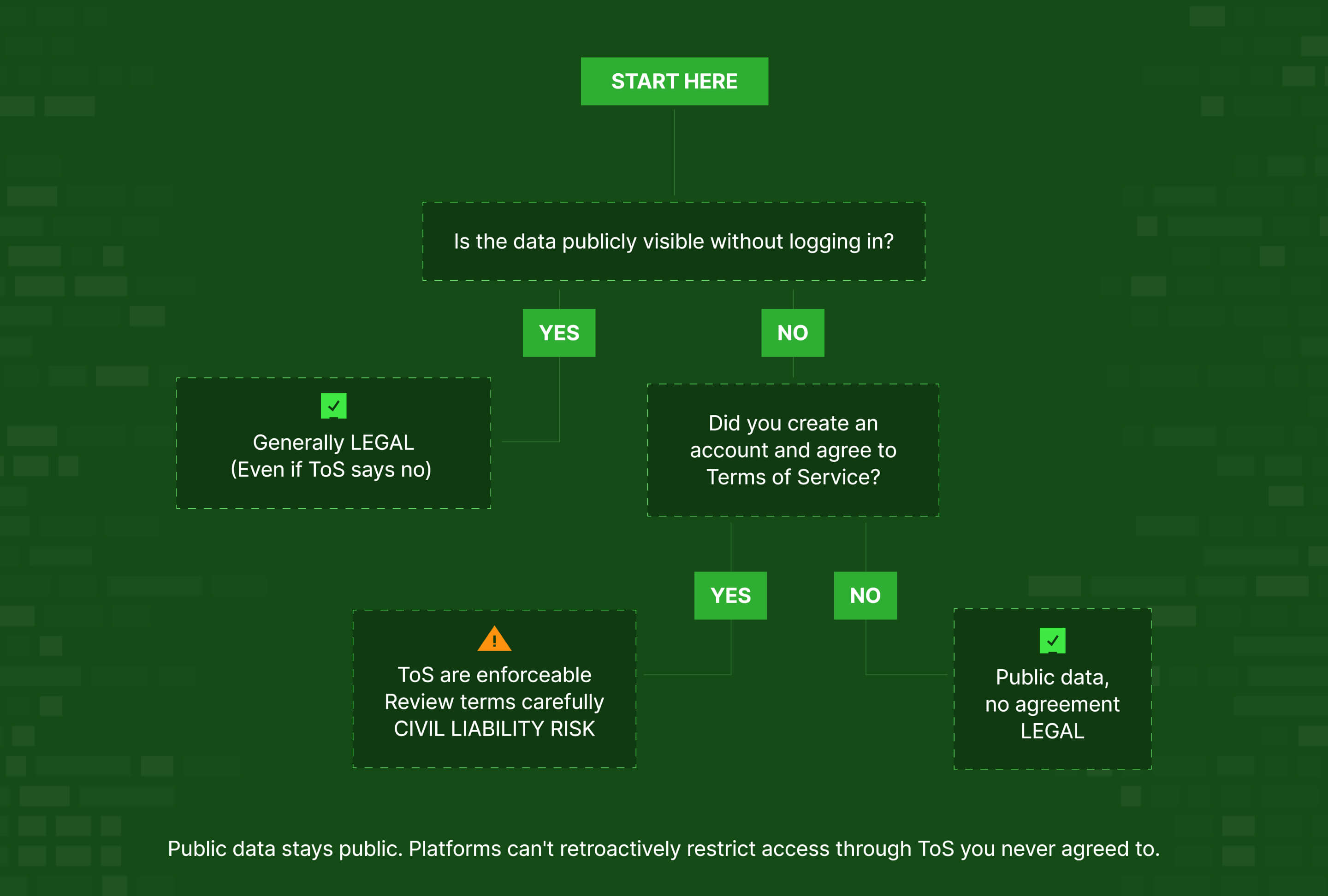
Question 1: Is the data publicly visible without logging in?
If YES → Collecting it is generally legal regardless of what the platform's Terms of Service say.
Courts have consistently held that websites can't make public data access "unauthorized" through ToS alone. As the Dutch court ruled in Ryanair v. PR Aviation, you can't bind someone to terms they never explicitly agreed to.
Question 2: Does accessing the data require creating an account or logging in?
If YES → You've agreed to Terms of Service that may prohibit scraping, and those terms are enforceable because you explicitly accepted them.
But what does the law say about data scraping? ⬇️
What The Law Says About Data Scraping
US legal framework
The Computer Fraud and Abuse Act (CFAA)
The Computer Fraud and Abuse Act was passed in 1986 as anti-hacking legislation. It prohibits "unauthorized access" to computer systems, which makes perfect sense for actual hacking.
But for years, this vague "unauthorized access" language created legal uncertainty around web scraping. Companies weaponized CFAA to threaten legal action against any automated data collection, arguing that scraping violated authorization provisions even when the data was publicly visible.
This chilled legitimate business activities and made companies unnecessarily fearful of collecting public data.
Recent court decisions have clarified the boundaries – and they're far more favorable to scraping than most companies realize. ⬇️
hiQ Labs vs. LinkedIn (2022)
hiQ Labs vs. LinkedIn is the case that rewrote web scraping law in the US.
hiQ Labs operated a workforce analytics platform that scraped public LinkedIn profiles to provide employee retention insights. LinkedIn sent a cease-and-desist letter claiming CFAA violations and blocked hiQ's IP addresses.
hiQ didn't back down. They sued, arguing that scraping public data can't be "unauthorized access" under CFAA.
The court agreed.
The Ninth Circuit Court of Appeals ruled decisively in hiQ's favor, establishing that:
- Accessing publicly available data doesn't violate CFAA
- Public data access isn't "unauthorized" even if the platform objects
- Companies can't use CFAA to prevent scraping of information they've made publicly accessible
The precedent
This decision drew a clear legal line: if data is viewable without authentication, collecting it doesn't constitute hacking under federal law – regardless of platform preferences or Terms of Service.
The court stated explicitly: "The CFAA's prohibition on accessing a computer 'without authorization' is violated when a person circumvents a computer's generally applicable rules regarding access permissions... but not when a person accesses a computer consistent with authorization and uses that access to obtain or alter information that falls beyond the scope of authorization."
In plain English: If the computer lets you in (no login required), you have authorization. What you do with publicly accessible information isn't an access violation.
Meta vs. Bright Data (2024)
This recent case reinforced and extended the hiQ principles, showing the legal trend continues to favor public data scraping.
Meta sued Bright Data for scraping public Facebook and Instagram data at scale. Meta argued this violated CFAA and constituted unauthorized access.
The ruling:
Federal court ruled in Bright Data's favor, finding:
- No evidence of wrongdoing in scraping public data
- Bright Data never accessed data behind login walls or circumvented security
- Public information remains public regardless of platform objections
Even tech giants with vast legal resources can't use CFAA to prevent scraping of their public data. The precedent is consistent and clear across multiple circuits: public data scraping is legal under federal law.
What CFAA prohibits
Based on these precedents and the Department of Justice's own guidance, here's what CFAA restricts:
❌ Bypassing authentication to access private accounts or data
❌ Circumventing technical security measures like CAPTCHAs or IP blocks
❌ Using stolen credentials or exploiting system vulnerabilities
❌ Accessing systems you don't have permission to access
What CFAA allows
✅ Automated requests to publicly accessible web pages
✅ Extracting data visible without authentication
✅ Scraping information even if platforms object via Terms of Service
⚠️An important distinction for publicly accessible data (no login required):
Courts have consistently held that Terms of Service restrictions on scraping aren't enforceable. That means you can't bind someone to terms they never explicitly agreed to.
As the Dutch court ruled in Ryanair v. PR Aviation: "A party cannot impose contractual obligations on another party without the latter's knowledge and consent." The analogy: you can't charge someone for reading a poster you've displayed in your shop window.
However, if you create an account and agree to Terms of Service that prohibit scraping, those terms become enforceable because you explicitly accepted them. Platforms can then:
- Terminate your account
- Block your access
- Sue for breach of contract
- Seek injunctive relief
Courts have made clear you can't make legal activity criminal by putting it in your Terms of Service. These are civil remedies, not criminal prosecutions. But civil liability is still liability, especially when you've voluntarily agreed to the terms.

The current US legal position (2026)
US courts have consistently established these principles:
- Public data is accessible. No authentication required = legal to scrape under CFAA
- ToS violations are contractual, not criminal. Breaking terms you agreed to might create civil liability but doesn't violate federal hacking statutes
- Methods matter more than intentions. How you collect data (respecting technical boundaries, not circumventing security) affects legality more than why you're collecting it
EU legal framework
The European approach to web scraping differs fundamentally from US law, reflecting a completely different philosophical starting point about privacy and data protection.
GDPR applies to all personal data
The most common GDPR misconception: that it only governs private or sensitive information.
GDPR applies to all personal data, regardless of whether it's publicly available.
If you scrape someone's publicly visible LinkedIn profile, that's personal data under GDPR. Public Instagram posts containing usernames trigger GDPR obligations. Even business contact information found on company websites constitutes personal data if it identifies individuals.
EU data protection law prioritizes individual privacy rights over business convenience or public accessibility.
Making information public doesn't waive your privacy rights under European law.
The six lawful bases for processing personal data
To legally process personal data under GDPR, you must have one of six lawful bases:
- Consent: The individual explicitly agreed
- Contract: Processing is necessary to fulfill a contract with the individual
- Legal obligation: Required to comply with law
- Vital interests: Necessary to protect someone's life
- Public interest: Processing serves important public function
- Legitimate interest: You have valid business reason, processing is necessary, and individual rights aren't overridden
For business web scraping scenarios, legitimate interest provides the only realistic lawful basis. The others simply don't apply to most commercial data collection.
What is legitimate interest?
Legitimate interest under Article 6(1)(f) requires passing a three-part test:
1️⃣ Purpose: Do you have a legitimate business reason for processing this data?
Market research, competitive intelligence, fraud detection, AI training – these can qualify as legitimate purposes. But you need to articulate the specific purpose clearly, not just say "business reasons."
2️⃣ Necessity: Is data processing necessary to achieve that purpose, or could you use less intrusive means?
If platform APIs provide adequate data, arguing necessity for scraping becomes harder. You need to explain why scraping is genuinely necessary, not just more convenient or comprehensive.
3️⃣ Balancing: Do individual privacy rights and interests override your business needs?
The European Data Protection Board guidance says to weigh:
- Nature and sensitivity of the data
- Reasonable expectations of individuals
- Social value of your purpose
- Safeguards you've implemented
Three core GDPR compliance requirements
Beyond having a lawful basis, GDPR imposes additional obligations:
1. Transparency requirements (Article 13-14)
You must inform individuals:
- That you're collecting their data
- What you're doing with it
- Their rights (access, deletion, objection)
This creates an obvious practical problem: you're collecting data from people you can't easily notify. Some companies address this through privacy policies on their websites, though whether this satisfies GDPR's transparency requirements for scraped data remains debatable.
2. Respect objections (Article 21)
Individuals have the right to object to processing based on legitimate interest. If someone opts out, you must stop processing their data. This requires mechanisms to receive and honor objection requests.
3. Data Protection Impact Assessment (Article 35)
High-risk processing requires formal DPIA documenting:
- What data you're collecting and why
- Risks to individuals
- Mitigation measures
- Legal basis justification
Three conditions for legal GDPR scraping
Know when Terms of Service apply
For public data accessible without login, ToS restrictions generally aren't enforceable – you never agreed to them.
However, if you create an account to access data, the ToS you agreed to become enforceable under contract law. This creates independent legal exposure beyond GDPR compliance.
Comply with direct marketing rules
GDPR severely restricts commercial prospecting. Using scraped data for sales outreach typically requires consent, not just legitimate interest.
Follow core GDPR principles
Common violations that trigger enforcement:
- Failing to inform individuals about data collection
- Not documenting your lawful basis
- Ignoring objection requests
- Inadequate security for stored data
What Legal Paralysis Can Cost Your Organization
Every day companies delay access to public data based on misconceptions, competitors who understand the actual legal boundaries pull further ahead.

Lost competitive intelligence
Your competitors aren't waiting for Meta's permission to understand consumer sentiment. They're analyzing the same publicly visible posts you could be examining – and making better product decisions, marketing strategies, and investment choices because of it.
When you limit analysis to API-available data (typically 10-20% of the actual conversation), you're making strategic decisions on radically incomplete information. According to social media research, 72% of US adults use multiple social platforms. But most APIs provide fragmented, incomplete data from each one.
Failed customer retention
Social listening platforms that only cover Twitter and Reddit because that's what the APIs provide are losing customers to vendors who understand the legal difference between "API doesn't provide it" and "it's illegal to collect."
A 2023 Gartner survey found that incomplete data costs organizations an average of $12.9 million annually in poor decisions, failed initiatives, and lost revenue opportunities.
Your customers need comprehensive insights across the platforms where their audiences actually spend time. If legal misconceptions prevent you from providing that coverage, someone else will, and they'll take your customers with them.
Missed market opportunities
Different industries need different types of public data access:
AI companies need diverse training datasets across sources and formats. The performance gap between models trained on comprehensive vs. limited datasets can exceed 30% on benchmark tasks.
Market research firms need cross-platform consumer insights that single-source APIs simply don't aggregate. The market research industry generates $47 billion annually, built largely on comprehensive data access.
Pharmaceutical companies need adverse event detection across all platforms where patients discuss treatments. FDA guidance explicitly acknowledges social media as a source for post-market safety surveillance.
If legal paralysis prevents you from serving these use cases effectively, you're not protecting the business, you're limiting its addressable market and growth potential.
The innovation penalty
Perhaps the highest cost is the innovation you never attempt because legal concerns have drawn invisible boundaries around what's "allowed."
Product features that would differentiate your offering remain unbuilt. Your roadmap says "pending legal review" while competitors ship features powered by comprehensive public data.
Market expansion into new verticals becomes impossible. You can't serve pharmaceutical companies who need social adverse event detection. You can't work with financial services firms who need real-time market sentiment across platforms. You can't help retail brands who need omnichannel consumer insights.
Partnership opportunities evaporate. When potential partners need capabilities you've rejected based on phantom legal restrictions, they find partners who actually understand the law.
The Bottom Line
Web scraping public data is legal when you do it correctly.
"Correctly" means five things:
- Access only genuinely public data. No bypassing logins, circumventing authentication, or accessing private accounts.
- Respect technical boundaries. Follow robots.txt conventions, implement reasonable rate limits (minimum 1-2 seconds between requests), don't degrade site performance.
- Handle personal data compliantly. If collecting personal data under GDPR jurisdiction, maintain documented legitimate interest assessments and proper safeguards. Better yet, focus on non-personal business data that avoids GDPR complexity entirely.
- Manage copyright risk through transformative use. Enterprise tools that aggregate social data for business intelligence, research, and cross-platform monitoring serve fundamentally different purposes than the original social platforms and constitute transformative use. Consult IP counsel about your specific use cases.
- Operate transparently. Use clear bot identification, provide contact information, and demonstrate good faith practices.
The question you should be asking isn't "Is web scraping legal?"
It's "How do we access the public data our business needs while staying compliant with actual laws?"
That reframe changes the entire conversation. It acknowledges that public data exists and provides business value. It recognizes that laws create specific boundaries, not blanket prohibitions. It focuses on execution instead of paralysis.
Most companies aren't prevented from accessing public data by law. They're prevented by misconceptions about what the law actually requires.
Moving forward
If your legal team is worried because they're confused about platform APIs, scared of "hacking" associations, or just uncertain about the actual requirements – share this with them.
You can build compliant scraping infrastructure yourself (requiring legal expertise, technical resources, and ongoing maintenance as platforms change). Or you can partner with specialized data providers who've already built compliance-first infrastructure and maintain it professionally.
The business cost of legal paralysis based on misconceptions consistently exceeds the manageable risk of collecting public data using proper compliance frameworks.
Don't let your competitors make better decisions with data you could be using too.
Ready to explore compliant public data access for your business? Book a demo to see how Datashake delivers comprehensive, compliant social media and review data – without the legal complexity of building and maintaining scrapers yourself.



More insights you might like

