Should You Build vs Buy Your Social Media Data Pipeline?

Turns out: very hard.
What looks straightforward – connect to a few APIs, collect some posts – has become one of the most expensive infrastructure decisions companies make in 2026.
Here's why: Social media platforms change constantly – and unpredictably. APIs can update weekly, daily, or break overnight with zero warning. This isn't build-once-and-forget infrastructure. It's a living system that demands constant attention and typically costs hundreds of thousands per year in maintenance most teams never budget for.
Meanwhile, your data team is small, budgets are tight, and stakeholders want insights faster than ever. The days of abundant venture funding are over. You need to do more with less.
Building isn't always wrong. Some scenarios justify it: truly unique data needs, social data as your core product, or dedicated teams for API maintenance.
But for most companies, the real question isn't "build or buy?"
It's: "How do we get reliable social data without accidentally becoming an API maintenance company?"
In this guide, you'll discover:
- Why social media APIs cost 10-100x more than expected in 2026, and why it's only getting harder and more expensive
- The platform-by-platform breakdown (Instagram, TikTok, Twitter/X, LinkedIn)
- Why teams now use unified social media API aggregators
- How to make the right decision for your specific use case
Let’s dive in. ⬇️
What is a Social Media Data Infrastructure?
Social media data infrastructure is the complete technical system that collects, processes, stores, and activates data from social platforms like Instagram, TikTok, Twitter/X, LinkedIn, Facebook, YouTube, and others.
Unlike general data pipelines that connect to databases or business applications, social media infrastructure deals with unique challenges.
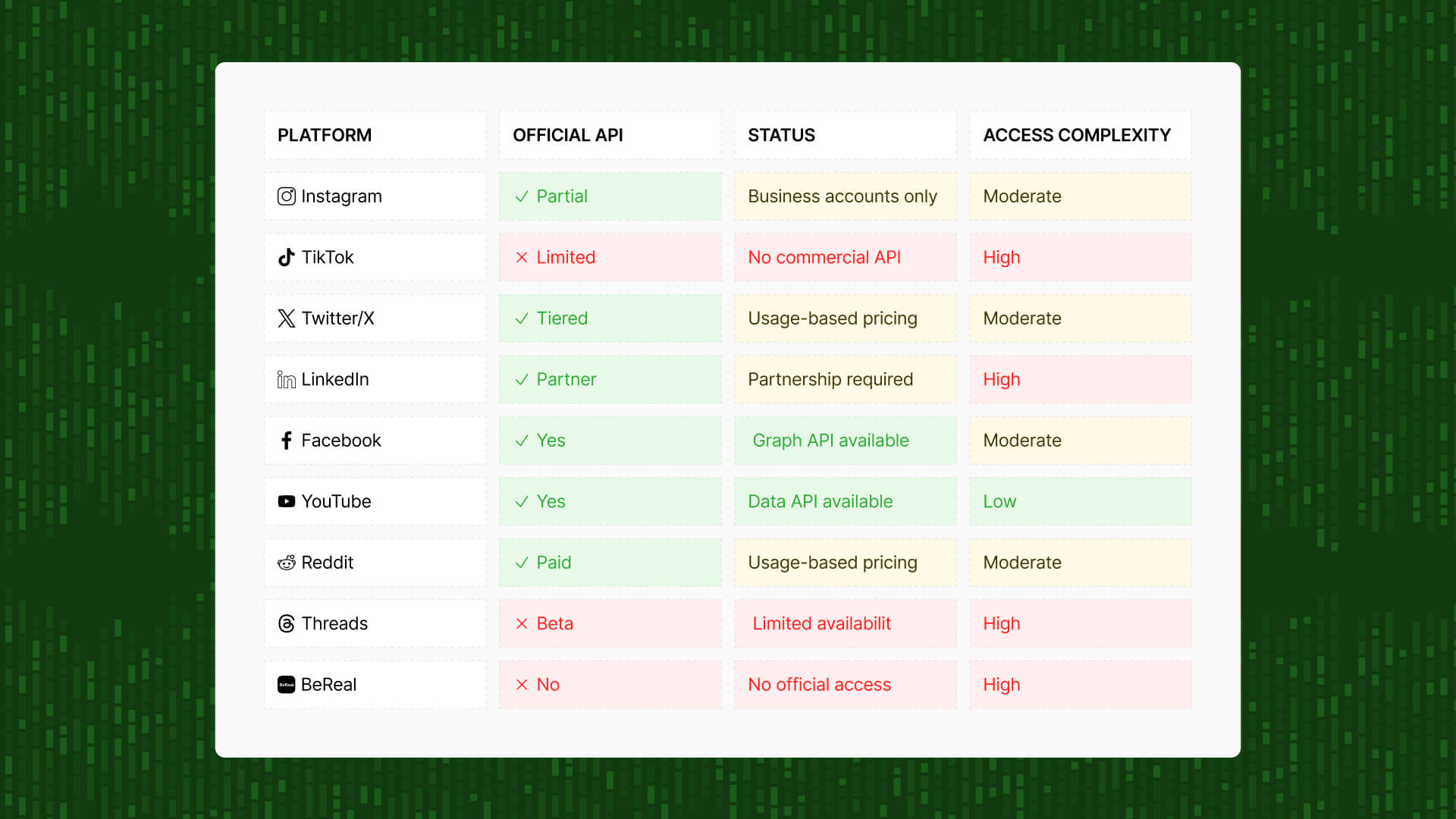
Perhaps the most challenging: several of the fastest-growing and most business-critical platforms offer no official API access at all.
Take TikTok. It's become essential for brand monitoring, influencer marketing, and social commerce. But TikTok offers no commercial API, even though businesses desperately need the data. And it's not just TikTok – the same challenge exists with BeReal, and regional platforms like WeChat.
What makes social media data different

1. Platforms change constantly
- APIs change quarterly (Instagram Graph API v22.0 as of 2025, with regular deprecations along the way)
- Access restrictions shift without warning
- Authentication requirements evolve (new OAuth scopes, stricter app review processes)
- Platform terms of service updates require continuous monitoring to stay compliant.
You need to be where people are talking, and people are constantly moving to new platforms. Staying on top of conversations and trends means being ready to add new sources at a moment's notice.
2. Every platform works differently
Each platform structures data differently. Twitter has "tweets," Instagram has "media objects."
Rate limits are all over the map: Instagram allows 200 requests per hour, Twitter Basic gives you 10,000 tweets per month, Reddit caps you at 100 requests per minute. Authentication methods vary too – OAuth 2.0, app tokens, user tokens.
3. Data comes in every format imaginable
You're dealing with text posts, images, videos, stories, reels, live streams.
Then there's the metadata: likes, comments, shares, views, engagement rates.
User data includes profiles, followers, demographics.
Plus temporal data: posting times, trending topics, hashtag performance.
It's a lot to wrangle into something consistent.
4. Compliance is a moving target
Platform terms of service vary dramatically from one to the next.
- Data retention policies differ (how long can you store posts?)
- PII handling has its own maze of requirements (user data permissions, GDPR/CCPA compliance)
- Some APIs even have commercial use restrictions that prohibit competitive use cases.
You need to track all of this, constantly.
The seven layers of social media data infrastructure
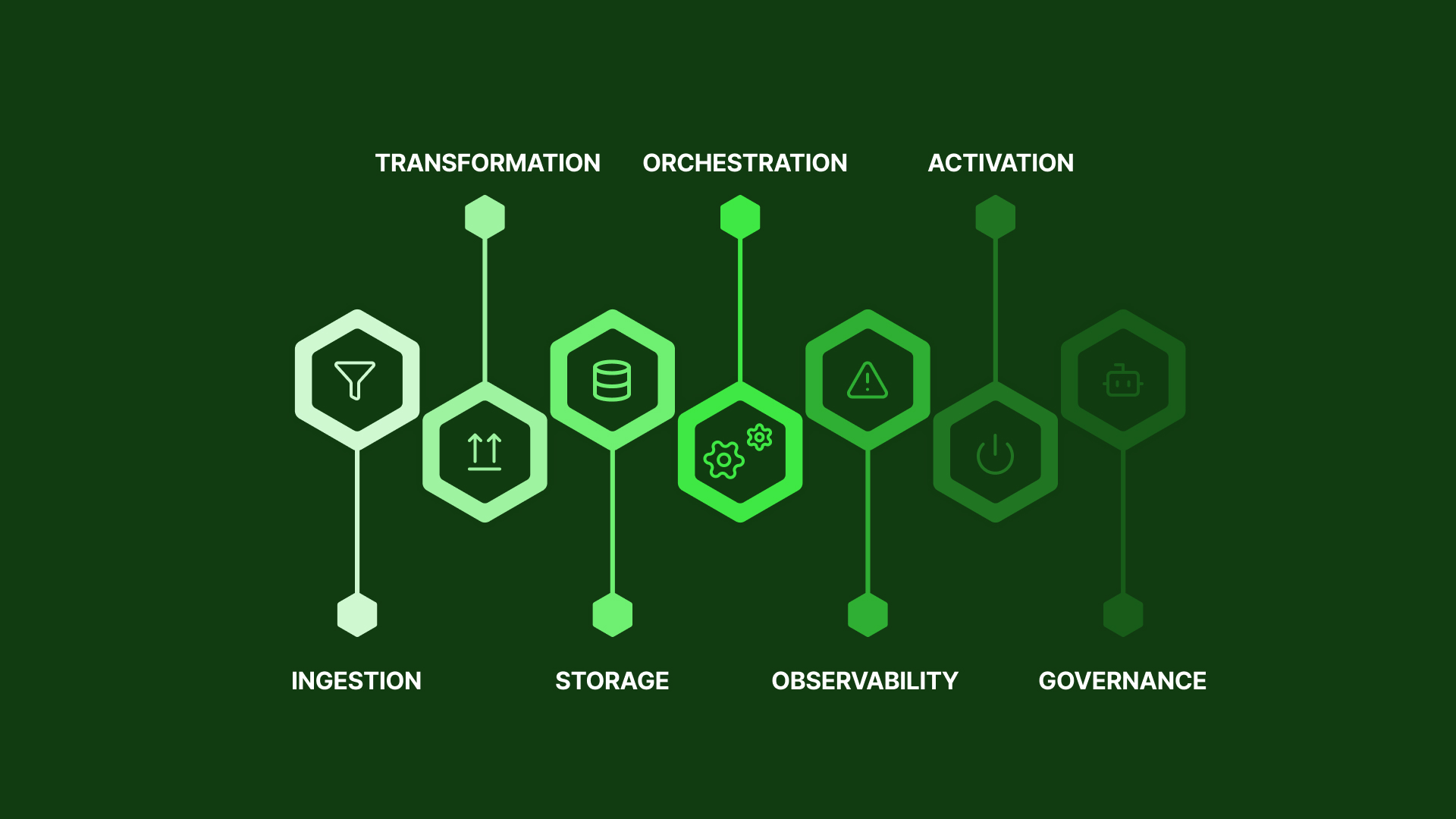
LAYER 1: Data Ingestion
Connect to platforms and extract data reliably. Sounds simple, right? Unfortunately, it's not.
Instagram has strict limits. Reddit charges $0.24 per 1,000 requests.
Building this yourself takes 3-4 weeks per platform upfront, then 5-10 hours every week just keeping it running.
LAYER 2: Data Transformation
Normalize platform-specific data so you can compare apples to apples. Twitter calls it favorite_count. Instagram calls it like_count. TikTok calls it digg_count. Same concept, different names everywhere.
LAYER 3: Storage
Store data at scale without breaking the bank. Videos average 20MB each. If you're collecting 1M posts per day and 30% include video, storage alone runs $4,140 per month. That's just for keeping the data, not processing it.
LAYER 4: Orchestration
Schedule data collection across platforms while respecting each one's rate limits. Feels a bit like conducting an orchestra where every instrument plays by different rules.
LAYER 5: Observability
Detect when platforms break or data quality tanks. Without this layer, you learn about problems from angry customers three days later. With it, alerts fire within 5 minutes and you can fix issues before anyone notices.
LAYER 6: Activation
Make social data useful through dashboards, analytics, and integrations. Because all that collected data means nothing if your teams can't act on it.
LAYER 7: Governance
Navigate platform terms of service, handle data privacy laws, and manage legal risk.
1️⃣ Building Your Social Media Data Infrastructure
In the early 2010s, collecting social media data was straightforward. Twitter offered unlimited free API access. Facebook's Graph API was open and well-documented. You could write a basic Python script, set up a cron job, and have data flowing within days.
Sadly, those days are gone.
Social media APIs went through huge shifts that transformed simple scripting into complex distributed systems engineering. ⬇️
Shift 1: Platforms recognized data as revenue
- Twitter/X eliminated its free tier in 2023
- Instagram fully deprecated its Basic Display API in 2024 and moved everyone to the Graph API
- Reddit moved to tight rate limits in 2023
- TikTok? Still largely closed with no clear path to commercial access.
Shift 2: Multi-platform monitoring became mandatory
Companies went from monitoring 2-3 social platforms to needing 10+.
- Instagram (posts, stories, reels, IGTV)
- TikTok
- Twitter/X
- YouTube
- Snapchat
- Threads
- Bluesky
- Truthsocial
- BeReal
- Telegram
- Parler
- 4chan
- Mastodon
Shift 3: Real-time became non-negotiable
Batch processing once a day? Completely unacceptable now. Brand monitoring needs to detect mentions within minutes. Crisis management requires immediate response when something goes viral, and trend detection needs hourly updates.
➡️ Today's "simple script" needs to handle:
- Rate limit management
- Authentication complexity
- Schema evolution
- Error recovery
- Monitoring
- Backfills
- Incremental loading
- Distributed architecture
- Cost optimization
- And compliance tracking.
Not so simple anymore.
But there's still this lingering belief that internal solutions are inherently superior. Maybe it's the appeal of the technical challenge. Maybe it's a perception that building demonstrates more skill than buying. But the reality is that your business's destiny is determined by business outcomes, not infrastructure ownership.
So what are the actual benefits of building? ⬇️
👍 The pros of building
You can tailor your data pipeline to your specific needs
When you build, you customize every aspect to your requirements.
Maybe your customer experience tool needs to combine Instagram comments with Tripadvisor reviews in a unified sentiment model. Or your social intelligence dashboard requires custom entity extraction that spots your customers' specific competitor brands.
You design for your specific data types, processing workflows, and transformations. Handle proprietary data formats vendors don't support. Integrate seamlessly with legacy internal systems.
💡 Datashake alternative: We provide raw, structured social data as a foundation. You build your proprietary models on top. You get customization where it matters (your algorithms and business logic) without building infrastructure (the data collection layer).
You control your tech stack
Choose the tools, frameworks, and technologies that fit your architecture.
Already invested heavily in Apache Kafka for event streaming? You can have social data flowing through Kafka topics.
All-in on AWS? Store social data in your S3 buckets and process it with Lambda functions.
Everything aligns with your strategy. You optimize performance, scalability, and security based on your organization's specific needs.
You build in-house expertise
Your team gains valuable experience along the way. Deep understanding of Instagram Graph API v22.0's nuances and undocumented behaviors. Expertise navigating Twitter/X's enterprise tier rate limits at scale. Institutional knowledge about which Reddit API patterns trigger rate limiting.
That knowledge stays with the company. Deep understanding of data flows means faster troubleshooting when things break. Your team becomes domain experts. No dependency on external consultants.
⚠️ Reality check: This specialized expertise typically doesn't exist in most internal teams. And honestly? It often doesn't need to.
Speed for very simple use cases
If you need data from exactly one platform for a very focused use case with absolutely no plans to expand, building a basic script might actually be faster than evaluating vendors.
⚠️ But here's what actually happens: This almost never stays simple. Within 6 months, someone asks "Can we also add TikTok?" (another several weeks of work). Then "Our competitor does Instagram too" (tracking expands). Then "Can we see historical trends?" (now you need a data retention strategy). Scope creeps fast.
Data sovereignty for regulated industries
For certain scenarios, this is critical.
HIPAA compliance means any social post mentioning patient experiences must be handled as protected health information. EU patient data can't leave EU data centers (GDPR plus local regulations), and the FDA expects complete data lineage for adverse event detection.
You get a complete audit trail under your control. You’re not granting third-party access to sensitive data. You can meet "data doesn't leave our premises" requirements for certain government and healthcare contexts.
💡 Datashake alternative: We built our entire approach around compliance from day one. Transparent data sourcing, full audit trails, regulatory documentation – all the compliance infrastructure regulated industries need, without you having to build it yourself.
👎 The cons of building
It takes time and costs a lot
Building social media data infrastructure is a months-long engineering commitment before you collect your first Instagram post.
- Months 1-2: Architecture design, technology selection, infrastructure setup
- Months 3-5: Build your first platform connector. Instagram Graph API alone requires app registration, business verification (taking 2-6 weeks), OAuth implementation, rate limit handling, and token management.
- Months 8-9: Add your third platform (Twitter/X API integration)
- Months 10-12: Fourth platform (LinkedIn partnership requirements or unofficial methods).
Total before production: 9-15 months.
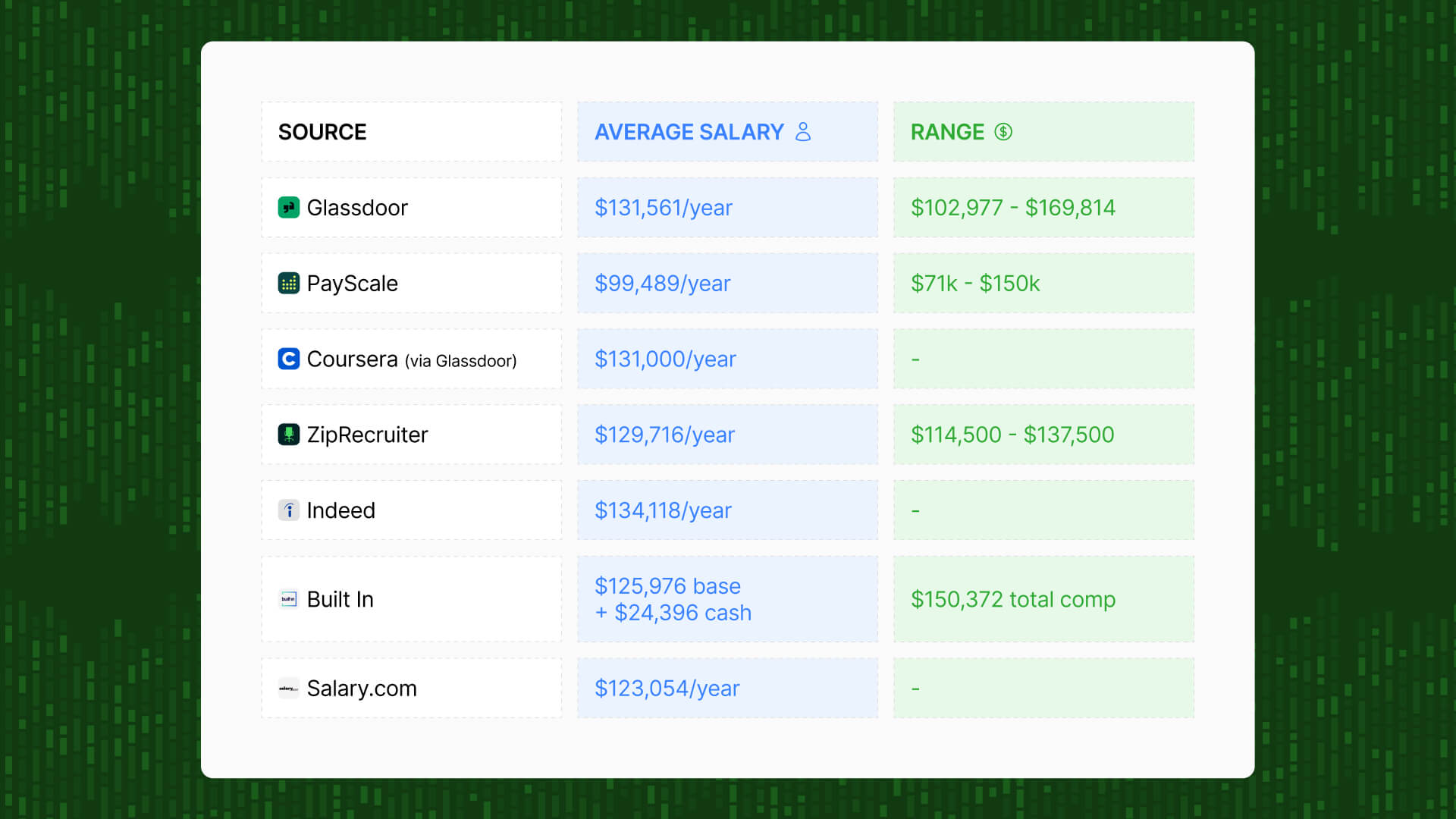
💸 The financial reality is that the average data engineer salary is $131,586 (Glassdoor). With 2-3 engineers working for 3-6 months, you're looking at $66,000-$197,000 before you see any production data.
Hidden human capital costs
It takes 6 months to hire a qualified engineer, then another 12 months before they're truly productive. That's 1.5 years before ROI. And engineers leave because tirelessly maintaining Instagram's API doesn't exactly lead to promotions.
You need a rare combination of skills: data engineering, social platforms expertise, compliance knowledge, and distributed systems experience. With 15-20% annual churn in tech, you're rebuilding institutional knowledge every 5-6 years.
Senior engineers spend 20-40% of their time training others instead of building. Infrastructure teams create dozens of hours per week in communication overhead alone. And you're competing with FAANG companies for this talent.
Ongoing maintenance is relentless
Typical data infrastructure maintenance runs around $520,000 annually. And that’s not even taking into account the complexity you get with social media platforms.
December 4, 2024: Instagram Basic Display API hit end-of-life overnight. Every personal account integration broke.
January 2025: Meta deprecated key Insights API metrics. Customer dashboards suddenly showed "N/A" for critical data.
October 2024: Instagram slashed rate limits from 5,000 to 200 calls/hour (96% drop) without warning.
Silent failure is the worst kind
Websites and APIs change constantly without a heads up. Monday you're collecting 10K posts per day successfully. Tuesday you're collecting zero posts. Not an error message in sight. It just silently returns empty results.
The burden of connector maintenance

Each connector requires hours of ongoing maintenance per week. ⬇️
- APIs impose rate limits you must respect and manage
- OAuth tokens expire and need rotation
- Schema changes in source systems break your transformations downstream.
And the thing is, the most critical platforms often have no APIs at all. TikTok – the fastest-growing social platform, critical for Gen Z/Millennial reach, essential for social commerce – offers no commercial API access.
Building your own access means navigating technical complexity, and playing cat-and-mouse with platform specificities.
You need highly skilled engineers
This requires serious expertise.
- Platform-specific knowledge
- Distributed systems skills
- DevOps expertise
And demand for skilled data engineers is sky-high. Top talent commands premium salaries and is notoriously hard to retain. Recruitment takes up to 2.5 months and costs up to $50,000 in fees. Then there's 2-3 months of onboarding before they're fully productive. And with 12-17% annual turnover in tech , you're constantly replacing people.
It creates frustration and burnout for your engineering team
83% of developers suffer from burnout.
Engineers struggle to keep pace with constant requests for new data sources. They get frustrated having to tell stakeholders that new requests will take several weeks to fulfill.
It's always reactive, never proactive. Your team feels like they're running in place while business needs keep accelerating. Stakeholder disappointment damages relationships across the company.
You'll become dependent on the original developer
Custom-built pipelines rely heavily on the people who built them. When those engineers move on, undocumented logic and one-off fixes become long-term liabilities.
All the context lives in one person's head. Documentation lags reality by months or years. Critical decisions made months ago have no recorded reasoning.
New team members spend months reverse engineering your own code just to understand what's happening.
There's a lot of infrastructure complexity
A real platform isn't just executing jobs. It requires scheduling, monitoring, logging, alerting, governance, and much more. Teams try to extend CI/CD tools like GitHub Actions into data platforms. This works at first. Then it doesn't.
Who's patching base images? Rotating certificates? Preventing Kubernetes from crashing at 2 AM? Using general-purpose tools for specialized data needs creates constant friction.
Compliance falls entirely onto you
Instagram App Review requires you to submit your app, provide a demo, explain data usage, and answer retention questions.
Rejection scenarios include:
❌ "Your use case doesn't align with our platform,"
❌ "Your retention policy violates our terms," or
❌ "You compete with Instagram."
Impact: your entire Instagram integration breaks and customers can't connect.
All responsibility and liability fall on your organization. And getting certifications (SOC 2, ISO 27001, HIPAA) costs $100,000-$500,000 and takes 6-12 months to obtain.
The opportunity cost is massive

Every hour spent on pipeline infrastructure is an hour not spent building actual product features. Every hour fixing parsing bugs is an hour not building revenue-impacting capabilities.
What could your engineers build instead? ML models that improve conversion. Product features that reduce churn. Optimizations that cut cloud costs. Customer-facing capabilities that actually drive revenue.
You end up with an inferior pipeline compared to vendors
When you DIY, you build a solution for today's problems. Historical data? Your build only captures data going forward from launch.
Datashake provides real-time plus years of historical archives for backfill. ➡️ Impact: you can't show customers trend analysis from before they signed up.
There are many barriers to accessing data yourself
Dramatic reductions in data volume per API call. Historical data access limited to 7-30 days only with no backfill capability. Rate limits slashed overnight.
Platforms increasingly withhold data: comments access gets restricted or removed entirely, engagement metrics get deprecated, user demographic data disappears. You're constantly fighting an uphill battle.
When building makes sense
Building isn't always wrong. But you need some pretty specific conditions for it to work out.
The ideal conditions for building
You'd need basically ideal conditions:
- No fixed timeline
- No stakeholder breathing down your neck asking when it'll be done
- A large, senior engineering team with actual capacity for major infrastructure projects
- Truly unique requirements that no vendor on the market can touch
- And zero budget constraints on engineering hours or ongoing maintenance.
An Integrate.io survey found 29% of companies regret their decision to build. The main regret? They massively underestimated maintenance costs. Building the pipeline is the easy part. Keeping it running for years is where teams get crushed.
2️⃣ Buying Your Social Media Data Infrastructure
The modern data stack has exploded with options. Flexible, cloud-native tools are everywhere now. This makes buying a much smarter move than it used to be.
And the market reflects this shift. Data pipeline companies are projected to grow from $12.3 billion in 2025 to $43.6 billion by 2032.
So what are the pros of buying your social media data infrastructure?
👍 The pros of buying
It gives you advanced technical capabilities immediately
Integrations to multiple platforms without writing a single line of code. Robust data transformation that business users can actually use. Connections to all your major data warehouses, BI tools, and visualization platforms already built.
The true differentiator: historical + real-time data combined. Show customers brand mentions from the last 3 years even if they signed up yesterday. Building this yourself? Technically possible, but building a proper backfill system is extremely complex and time-consuming.
- Automated workflows come standard
- Engagement drops? Automatic alert
- Instagram adds metrics? Instantly available
- Hit a rate limit? System backs off and resumes.
Advanced monitoring included: platform health checks, data lineage, ML-powered anomaly detection. Building this yourself would be a massive project.
It gives you significant resource efficiency
Small teams benefit most here. If you've got 3-5 engineers total, you simply can't dedicate 2-3 of them to social infrastructure. With a data provider, those same engineers build product features customers actually pay for.
And it's not just engineers who benefit. Non-technical stakeholders – marketers, analysts, product managers – can configure data collection themselves. "Add Reddit tracking for our subreddit" goes from a 3-week engineering project to a 5-minute configuration.
Speed and immediate capability
The timeline difference is huge. With a data provider: API key, configure platforms, data flowing within 1-2 days. Building yourself: 9-15 months for 4 platforms.
You skip the entire trial-and-error phase. No learning the hard way about Instagram's rate limit quirks, or wasting weeks on Twitter's unpredictable pricing. The data provider already solved every edge case, platform quirk, and failure mode.
There's nothing to maintain
The provider handles broken scripts, infrastructure scaling, all of it.
You focus on using the data. Your team builds insights and features. The infrastructure just... works. It fades into the background where it belongs.
The maintenance burden exists for everyone. The question is who bears the cost. Vendors distribute maintenance across their entire customer base. They maintain the Instagram connector for 20,000+ customers. Cost per customer: maybe $100/month. You maintain it for yourself alone. Cost: $2,000/month.
You also benefit from fixes made for other customers' edge cases. Customer A discovers Instagram rate limits are stricter in Germany. Datashake fixes it for everyone. Customer B needs GDPR-compliant data retention.
Datashake builds it, you inherit it automatically. You get solutions to problems you haven't even encountered yet.
Your costs are predictable
Building feels "free" at first, but costs spiral quickly. Engineering time. Cloud costs. Emergency firefighting. It all adds up unpredictably.
Data-as-a-service gives you a predictable spend model, without surprise downtime eating into your budget.
Finance teams love this – predictable OpEx beats variable CapEx every time. You can forecast annual data infrastructure costs accurately and negotiate contracts with price visibility for multi-year planning.
You get access to built-in expertise and support
Providers have years of accumulated technical expertise. They've tested across thousands of customer configurations. They know how Instagram's API behaves differently in the EU vs US vs APAC. They understand pharma compliance requirements, finance KYC needs, retail product tracking nuances. They know what breaks at 100K posts/day vs 1M posts/day vs 10M posts/day.
While you're sleeping, they're keeping an eye out. Issues get resolved before you notice.
You maintain flexibility and customization
Buying doesn't mean one-size-fits-all.
- Select only the platforms you need – Instagram + TikTok but skip LinkedIn + Twitter
- Collect engagement metrics only and skip media files to reduce storage costs
- Configure frequency based on use case: real-time for brand monitoring, hourly for analytics, daily for reporting
- Apply geographic filters for GDPR compliance
- Set language filters for your target markets
- Custom data pipelines are available when you need them
- Define your own transformation rules
- Build custom engagement scoring formulas
- Set up campaign attribution with your UTM parameters and conversion tracking logic.
💡 Datashake provides the foundation – clean, structured, normalized social data. Your differentiation comes from what you build on top. You get infrastructure reliability from the data provider plus competitive advantage from your IP. The best of both worlds.

You get built-in compliance
Providers have established frameworks, audit logs, and filtering logic already built. They handle the technical complexity of navigating platform terms, consent requirements, and data privacy regulations. Most vendors maintain SOC 2, ISO 27001, and HIPAA certifications.
Legal teams monitor regulatory changes full-time and update systems automatically. Audit trails exist for compliance documentation. Data encryption at rest and in transit is standard.
You get high availability and scalability
High availability and scalability features come by default. The system maintains reliable performance even under heavy loads. Traffic spikes from Black Friday, viral moments, or product launches trigger automatic infrastructure scaling.
Your pipeline updates automatically in the background
➡️ New platform launches like Threads? Datashake adds the connector within weeks. You get immediate access without any engineering project.
➡️ Instagram launches Collabs? Datashake adds that data to the standard schema within days. Your dashboards automatically show Collabs metrics. Without any code changes required.
New connectors are added as they become available, and API changes are handled automatically. Without your team ever writing a line of code for maintenance.
You can empower non-technical users
One of the biggest advantages of buying is democratizing data access. Your business teams can work with data independently instead of constantly waiting on engineering.
What this looks like in practice
Marketing teams set up the data tracking they need. Analysts build their own reports. Product managers pull the insights they're looking for. Executives view real-time dashboards. All without filing engineering tickets or waiting weeks for help.
How vendors make this possible
Different teams need different tools, so vendors provide multiple interfaces:
- SQL interfaces for analysts who want granular control
- No-code configuration for marketers and business users who don't code
- Visual drag-and-drop builders that make pipelines accessible to everyone
- Real-time previews so you can see exactly what your data will look like as you configure it
When business users can work independently, they iterate faster. They’re able to slash engineering bottlenecks, and get rid of the two-week backlogs just to add a new data source or build a report. Time-to-insight drops from weeks to hours.
You can easily power new GenAI and low-code initiatives
Gartner estimates that in 2026, developers outside formal IT departments will account for at least 80% of the user base for low-code development tools. That shift is happening now, and clean social data enables it.
The data comes structured and ready for training
- Build sentiment models with pre-labeled social data for fine-tuning
- Create influencer scoring with historical engagement patterns for ML algorithms
- Develop trend prediction with time-series social data for forecasting models
- Train image analysis with social media images plus metadata for computer vision.
Real-time feature pipelines enable ML inference at scale. Live social data feeds directly into models for real-time predictions.
➡️ Example: customer mentions your brand on Twitter, sentiment score generates instantly, automated response triggers in under 60 seconds.
You can use social media posts as a knowledge base for AI assistants. Enable semantic search: "Find Instagram posts similar to this viral video." Build recommendation engines: "Find influencers with audiences similar to this creator."
👎 The cons of buying
Licensing fees can accumulate
You'll pay upfront licensing fees or ongoing subscriptions, and those costs can accumulate as your data infrastructure scales.
Pricing models vary, but they all have the same basic principle – as you use more, you pay more:
- Data volume pricing scales with your business growth (great when you're small, expensive when you're successful)
- Monthly Active Rows (MAR) pricing can be hard to forecast accurately (surprise bills are never fun)
- Seat-based pricing means every new team member increases your costs
- Feature-based tiers lock advanced capabilities behind higher pricing levels
You have limited control over technology stack
When you buy, you're bound by the vendor's constraints and limitations. That platform is what you get, and customizations are possible but not as free as if you were building yourself.
Here's what that means in practice ⬇️
- Can't touch the code. Closed-source vendors don't expose their internals. If something doesn't work the way you need, you can't fix it yourself.
- Feature requests go into a black hole. Need a specific capability? You're dependent on the vendor's roadmap.
- API limitations. You're constrained by what the vendor exposes programmatically. If they don't provide an endpoint for something, you're stuck.
- Integration restrictions. You can only connect the tools the vendor supports.
- Schema constraints. You must work within the vendor's data model expectations. Have complex business logic that doesn't fit their paradigm? You'll need workarounds.
The tradeoff is clear: you gain speed and reduced maintenance, but you sacrifice control. For most companies, that's a worthwhile exchange. But it's worth understanding what you're giving up.
💵 The True Cost of Build vs. Buy
The total cost of building your own pipeline almost always exceeds buying from a vendor. The "savings" of building in-house look good on paper – until you account for everything.
Let's break it down ⬇️
1. Setup and maintenance costs
BUILD
Engineering salaries are just the start
The average data engineer makes $131,586 per year. For a 3-6 month project with 2-3 engineers working full-time, here's what the cost looks like:
- Aggressive timeline: 3 engineers × $131,586 × 0.5 years = $197,379 before the pipeline reaches production
- Conservative timeline: 2 engineers × $131,586 × 0.25 years = $65,793
And that's just base salary. Add benefits, overhead, equipment, and office space (typically 30-50% on top of salary), and the loaded cost per engineer jumps to $171,062-$197,379/year.
Infrastructure during the build
You need environments to build in:
- Development environments: $500-2,000/month
- Testing infrastructure: $1,000-5,000/month
- Staging environments: $2,000-10,000/month
Over a 6-month build: $21,000-$102,000
Tooling and software
- Development tools and IDEs: $500-2,000/month
- Monitoring during development: $500-2,000/month
- Cloud services during build: $2,000-10,000/month
Total over 6 months: $18,000-$84,000
Recruitment and onboarding (if you're hiring)
Don't have the engineers yet? Add recruiting fees of $20,000-$50,000 per engineer (typically 15-25% of first-year salary). Then wait 2-3 months for onboarding before they're fully productive. Training and ramp-up costs another $5,000-15,000 per engineer.
Hiring 2 new engineers: $50,000-$130,000 before they even start building.
Total build setup costs: $161,583-$532,583
And you haven't collected a single data point yet.
Engineering salaries for ongoing maintenance
The typical maintenance cost for data infrastructure runs $520,000 per year. Here's the breakdown:
- 2-3 data engineers full-time: $288,778-$433,167/year (maintaining connectors, handling API changes, fixing bugs)
- 0.5 DevOps engineer: $72,195-$108,292/year (infrastructure, monitoring, scaling)
- 0.25 Security engineer: $36,097-$54,146/year (compliance, audits, vulnerability patches)
- On-call compensation: $10,000-$30,000/year (weekend/night coverage for production incidents)
Total salaries: $407,070-$625,605/year
Infrastructure costs that never stop
Production isn't free. Your running costs include:
- Production compute: $5,000-$50,000/month
- Storage: $2,000-$20,000/month
- Networking: $1,000-$10,000/month
- Monitoring/logging: $1,000-$5,000/month
Most painfully, self-managed infrastructure typically runs with 30-50% idle capacity waste. You over-provision to handle peak loads, meaning you're paying for resources sitting unused most of the time.
Total infrastructure: $108,000-$1,020,000/year
With 40% waste factor: $151,200-$1,428,000/year
Ongoing tooling costs
- Orchestration: $12,000-$36,000/year
- Monitoring tools: $12,000-$60,000/year
- Security scanning: $5,000-$20,000/year
Total tooling: $29,000-$116,000/year
Specific maintenance tasks
These are the fires your team will have to fight every month:
- Network outages from external APIs: 2-4 hours/month = $4,608-$9,216/year
- API rate limit management: 2-4 hours/month = $4,608-$9,216/year
- Bugs requiring backfills: 4-8 hours/month = $9,216-$18,432/year
- Schema changes disrupting transformations: 4-8 hours/month = $9,216-$18,432/year
- Data volume changes: 4-8 hours/month = $9,216-$18,432/year
- Data quality optimization: 4-8 hours/month = $9,216-$18,432/year
- Security patches: 2-4 hours/month = $4,608-$9,216/year
Subtotal: $50,688-$101,376/year
Connector-specific maintenance
Each connector needs constant attention. API changes. Authentication updates. Schema drift. Error handling improvements.
- Per connector maintenance: 2-4 hours/week = 104-208 hours/year
- For 10 connectors: 1,040-2,080 hours/year = $71,760-$143,520/year
Every new data source multiplies your maintenance burden.
Compliance and audit costs
Building doesn't exempt you from compliance, on the contrary:
- Annual SOC 2 audit: $20,000-$50,000/year
- Penetration testing: $10,000-$30,000/year
- Compliance documentation: 40-80 hours engineer time = $2,760-$5,520/year
Total compliance: $32,760-$85,520/year
Total annual build maintenance costs: $668,878-$2,328,021/year
Conservative estimate: ~$670,000/year
Aggressive estimate: ~$2.3M/year
And this is every single year.
BUY
Vendor costs stay predictable. You pay a known licensing fee. The vendor absorbs all the maintenance burden, infrastructure scaling, compliance updates, and platform changes.
Build costs don't stop after year one. They continue – and they escalate. Every single year, you're paying salaries, cloud infrastructure, and maintenance. Your team needs to keep the system running, add new data sources as platforms evolve, patch security vulnerabilities, handle API changes, and scale infrastructure as your data volume grows.
Vendor costs, by contrast, stay predictable. You pay a known licensing fee. The vendor absorbs all the maintenance burden, infrastructure scaling, compliance updates, and platform changes. Your costs might increase as your data volume grows, but they're contractual and forecastable.
How to Make the Build vs. Buy Decision
You've seen the numbers. Building costs $4.19M-$7.93M over three years. Buying is a fraction of that. But maybe you're thinking, "But our situation is different."
Let's figure out if you're in the 5% who should actually build, or the 95% who should buy. ⬇️
1. How fast do you need to move?
In social data, speed determines who wins. Your competitor launches a listening tool in 3 weeks using a vendor. You're still 9-15 months away from production if you're building for just 4 platforms (Instagram, TikTok, Twitter/X, LinkedIn).
Build timeline: 9-15 months to production
Buy timeline: Days to weeks to first insights
Can you afford to be that far behind?
2. Do you actually have the resources?
Do you have:
- 2-3 engineers you can dedicate full-time? Most teams don't. Small teams wear multiple hats, but your engineers are likely already at capacity.
- $72,000-$216,000 to spend before you even reach production? That's just the salary cost for 2-3 data engineers working 3-6 months.
- A product roadmap that can wait? Because while you're building infrastructure, your stakeholders are asking "where are my features?" Customer requests pile up. Revenue-generating work gets delayed.
Can you allocate this capacity?
3. What functionality do you actually need?
Most social media analytics platforms need the same core capabilities:
- Multi-platform data collection
- Normalized schemas (because every platform formats data differently)
- Engagement metric standardization
- Real-time plus historical data access
- Rate limit management
- Token refresh automation
- Data quality monitoring
- Compliance documentation
Datashake provides all of these out of the box.
Ask yourself this for each custom requirement: Does this functionality actually differentiate your business? Or are you just rebuilding what vendors already offer?
4. What's the real total cost?
We covered this extensively above. Build costs $4.19M-$7.93M over 3 years when you account for setup, maintenance, infrastructure, tooling, compliance, and all the hidden costs.
But there's one cost that's easy to overlook...
5. What are you NOT building instead?
Opportunity cost is often ignored.
But every hour your engineers spend on infrastructure is an hour they're not spending on:
- Features your customers are requesting
- Products that generate revenue
- Solving critical business problems
- Building competitive advantages
Opportunity cost: $1.4M-$5M per year in unrealized value from your engineering team.
Your data engineers didn't join your company to maintain API connectors. They joined to solve interesting problems and build valuable products. Infrastructure work burns them out and drives turnover.
How complex is your data landscape?
Number of sources matters enormously:
- 5 sources? Manageable
- 50 sources? Maintenance nightmare
Data types add complexity:
- Structured data (clean tables): relatively straightforward
- Semi-structured (JSON, XML): more parsing required
- Unstructured (text, images, video): significantly harder
Storage decisions:
- Data warehouse? Data lake? Data lakehouse?
- Each has different trade-offs for cost, performance, and query patterns
Analysis requirements:
- Batch processing (daily updates): simpler infrastructure
- Near-real-time (hourly): moderate complexity
- Real-time streaming (seconds): 5-10x more complex than batch
And real-time has basically become table stakes now.
Can you scale when you need to?
What works for 5 data sources falls apart at 25 sources.
Building often feels cheaper upfront because you're solving for today's needs. But consider your growth trajectory:
- 5 sources today
- 25 sources next year
- 50 sources in 3 years
Maintenance doesn't scale linearly. It scales exponentially. Each new source adds complexity that compounds with everything else.
Are you ready for things to break?
Because they will. All the time.
- Websites change without warning
- APIs evolve without notice
- Network outages happen
- Rate limits hit unexpectedly
- Schema changes surprise you
With vendors: They handle all of this.
What about sources without APIs?
Not every platform offers clean API access. Some require:
- Manual data transformation
- Custom web scraping
- Reverse engineering undocumented endpoints
Building a custom connector takes 2-4 weeks each. And there's a long-tail problem: 80% of your value comes from 20% of sources. But your stakeholders will want that other 80% of sources eventually.
What happens after you launch?
Even after your pipeline reaches production, you're not done. You still need:
- Data normalization: Every source has different formats and schemas. You need to standardize everything.
- Currency conversion: If you're collecting multi-currency data, you need exchange rate management and historical conversion rates.
- Data grouping: Aggregating across different dimensions (time, geography, product, campaign).
- Calculated metrics: Deriving metrics like CTR, ROAS, LTV, engagement rate from raw data.
- Data enrichment: Augmenting with third-party data (demographic info, sentiment scores, industry benchmarks).
- Report building: Creating visualizations and dashboards that stakeholders actually understand.
Meeting varied access needs:
- Marketers want spreadsheets
- Analysts want SQL access
- Data scientists want raw files
- Executives want simple dashboards
This post-implementation complexity is almost always overlooked in initial planning. Teams assume "once it's built, we're done”, but in reality, you're never done.
So, Should You Build or Buy Your Social Media Data Infrastructure?
Here's the question that should drive every decision:
Where should you invest your limited engineering resources?
Creating and maintaining data integrations?
OR
Creating actual business value?
Buy what you can. Build what you can't
BUY these things:
- Data connectors and integrations
- Storage infrastructure
- Orchestration platforms
- Observability and monitoring tools
- Activation and reverse ETL
These are commodity components. They're infrastructure. Dozens of vendors do this better than you ever will because it's their entire business.
BUILD these things:
- Your unique business logic and transformation rules
- Proprietary ML models and algorithms
- Whatever truly differentiates your business from competitors
This is where your engineering talent should focus – what creates competitive advantage.
The good news
The chance of finding existing software that covers your needs is extremely high.
The data pipeline market is growing from $12.3B in 2025 to $43.6B by 2032. That massive growth has created an ecosystem of hundreds of specialized vendors for every layer of the stack.
Your engineering team didn't join your company to babysit API connectors. They joined to build products, solve interesting challenges, and create value.
Let them do that work.
Still not sure?
If you're not sure whether you're in the 5% who should build or the 95% who should buy, book a 30-minute call with the Datashake team.
We'll walk through:
- Your requirements
- Platform needs and data sources
- Team capacity and expertise
- Growth trajectory
Then we'll give you an honest recommendation – even if that means building actually makes more sense for your situation.
We'd rather you make the right decision than sell you something you don't need.



More insights you might like


%20thumbnail.jpg)