Why Your Social Media Data is Incomplete

Walk into any marketing meeting where someone's presenting social listening insights, and you'll see the same thing.
Sharp dashboards. Sentiment scores. Engagement trends. Everyone's focused on how to analyze the data.
But there's a more fundamental question: What are you analyzing?
If your social listening tool only monitors Twitter and Reddit, you're not doing social listening. You're doing platform monitoring of a specific demographic. Looking at only a small portion of data.
Social conversations happen across 30+ platforms. TikTok (1.7B users), YouTube (2.7B users) – each with distinct audiences.
So why aren’t you getting the full picture of the data you need, and what can you do to change that?
Keep reading to find out:
- Why API rate limits stop collecting data when you need it most
- How platform sampling returns a fraction of results without telling you
- And which infrastructure alternative captures all 30+ platforms where your customers talk. ⬇️
You’re Making Decisions on Skewed Data: Here’s Why
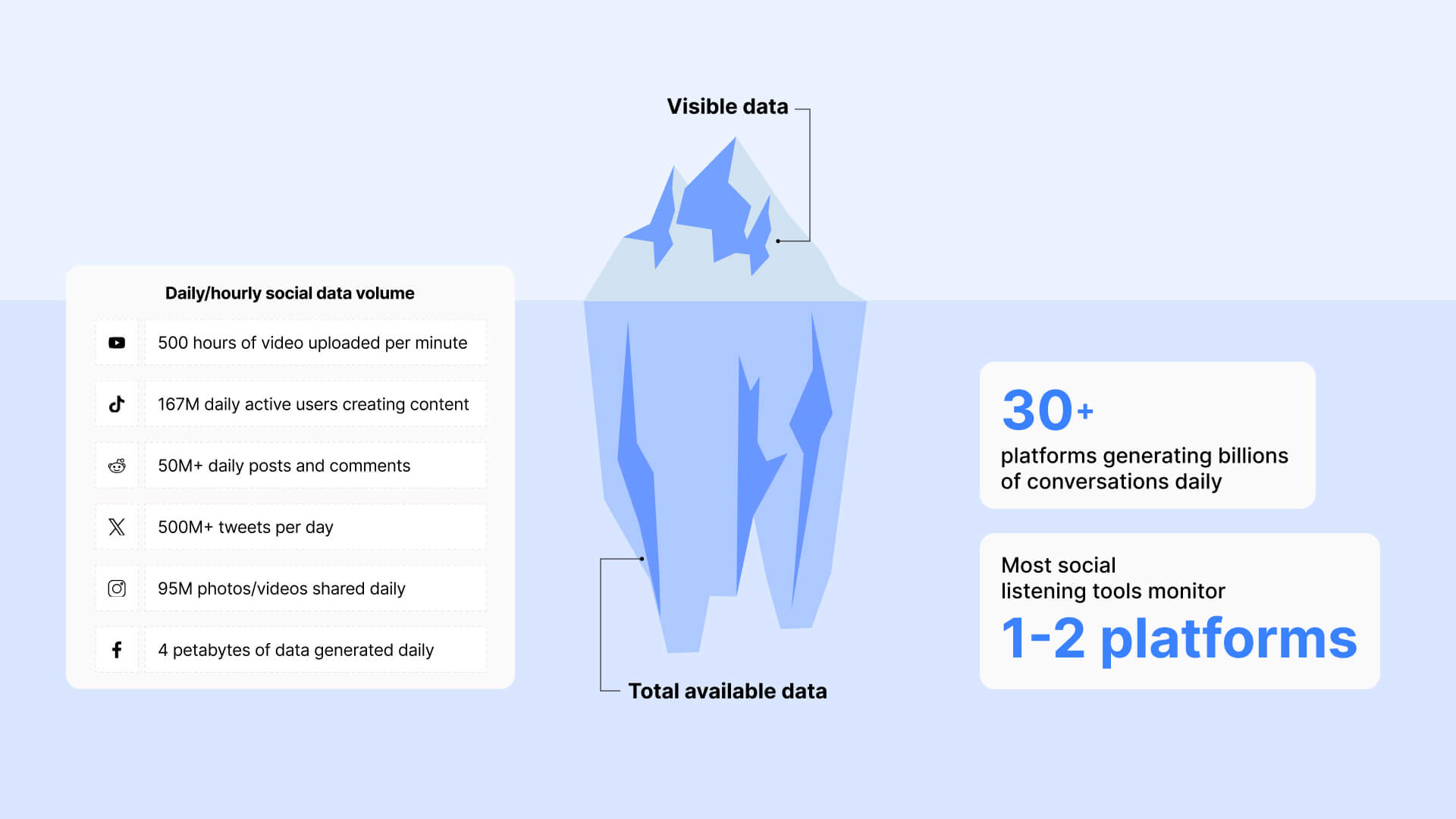
Social conversations happen across 30+ platforms – each with distinct audiences, content formats, and cultural norms.
TikTok reaches 1.7 billion people with short-form video. YouTube has 2.7 billion monthly active users leaving comments on videos – reviews, tutorials, discussions, testimonials.
Missing these platforms means you're looking at an entirely different picture, one that systematically overrepresents certain demographics while completely excluding others.
The skew happens on three levels simultaneously:
- Social data is not one platform. Every platform you don't monitor is an entire demographic segment you're blind to.
- Social data is not one demographic. When your tool is 70% Twitter data, you're hearing from young, male, tech-focused voices – likely not your actual customer base.
- Social data is not one language, one country, or one algorithm. Global brands making decisions on English-only, US-centric data are flying blind in a huge chunk of their markets.
But the question isn't just "are we missing some mentions?"
It’s: "Are we fundamentally misunderstanding our market because we're only listening to a narrow slice of it?" ⚠️
Social data is not one platform: the diversity imperative
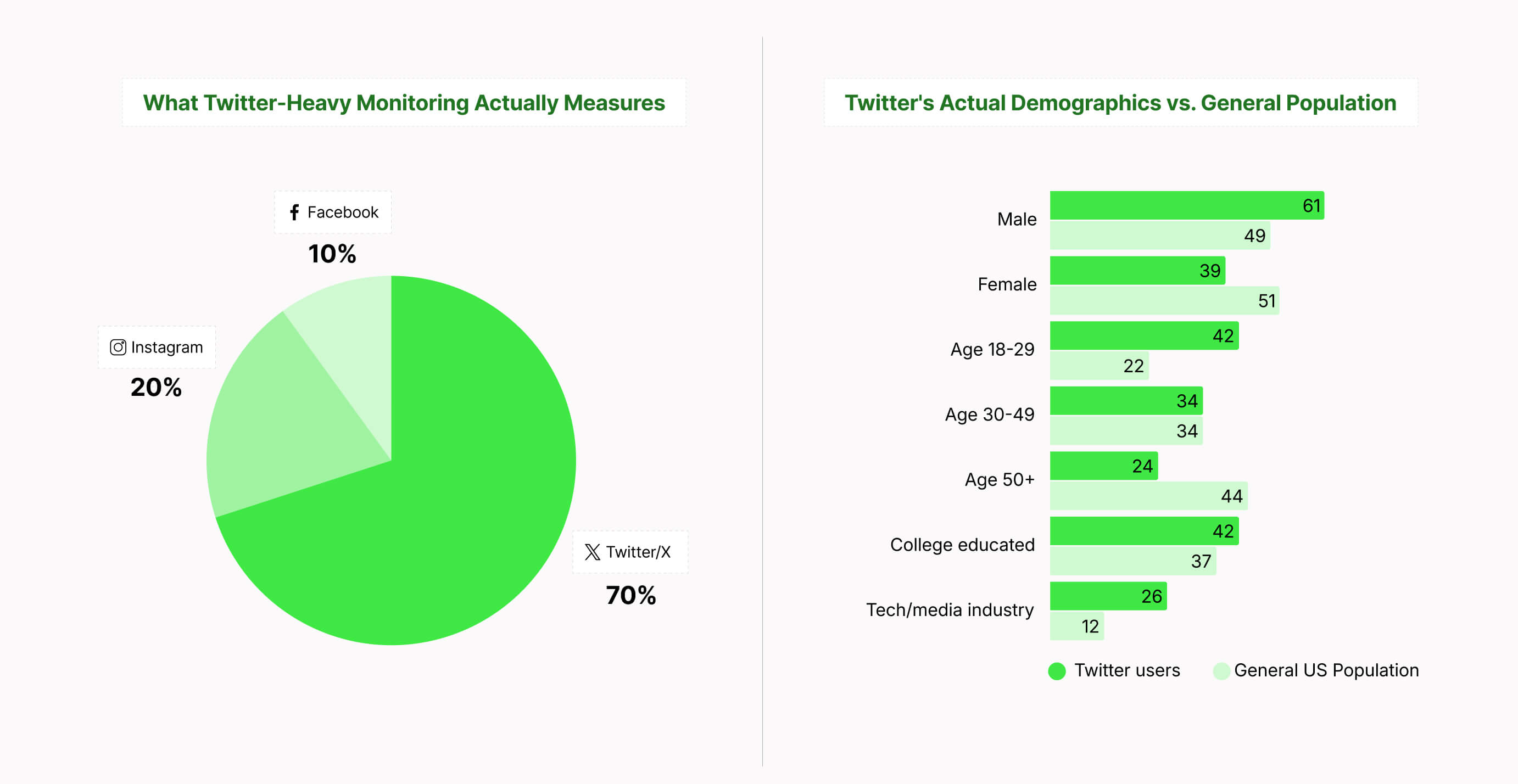
According to GlobalWebIndex research, the average internet user actively uses 7.5 social platforms monthly.
When you monitor only Twitter and Reddit, you're capturing an overlapping demographic slice – young, urban, digitally native users.
- 63.7% of Twitter’s user base is male
- A third of Twitter users are younger than 34
- Most Twitter users are located in the United States
- Twitter users tend to have a higher income
Meanwhile, entire audience segments are having conversations you never see:
- Gen Z on TikTok
- Purchase research on YouTube
- Professional discourse on LinkedIn
- High-intent communities: Product Hunt, industry-specific forums
- Visual discovery on Pinterest
- Q&A intent on Quora
- Thought leadership on Medium
- Review platforms: Yelp, Trustpilot, G2/Capterra, App Store/Google Play reviews
- Regional platforms: WeChat, Weibo, VK, LINE, KakaoTalk
- Niche professional networks: Behance, Dribbble, GitHub, ResearchGate
- Industry-specific forums: Trade-specific communities, hobbyist forums, brand-specific communities, subreddits for specialized interests
Young + Urban + Digitally Native + English-Speaking + US/UK-Centric = A fraction of your actual market. Each missing platform in your data pipeline is an entire demographic blind spot.
If limited platform monitoring creates these systematic biases, what does unbiased, complete data require? ⬇️
What "Complete" Social Media Data Means
The difference between comprehensive and complete data can lead you to make decisions based on a fraction of the real picture.
Complete vs. comprehensive: a critical distinction
Comprehensive means a wide range of metrics, sources, and analysis features. It's what vendors put in their glossy brochures: sentiment analysis, influencer identification, trend detection, demographic breakdowns, competitive benchmarking.
Complete means actually capturing every relevant data point within your parameters. It's what you actually need to make decisions you can stand behind.
➡️ Think of it this way: A tool can monitor 50 different metrics across three platforms (comprehensive) while missing 70% of the actual conversations happening on those same platforms (incomplete).
And the thing is, you can't analyze data you never collected.
Dashboards can’t fix blind spots. Better queries can’t fix missing sources. Advanced sentiment analysis doesn't help when most customer conversations happen on platforms you're not monitoring.
Social listening fails before analysis begins if the data foundation is incomplete.
Why complete data makes all the difference
According to statistical sampling principles, when you're doing market research that'll inform real business decisions, you need a representative sample. That means:
- Your demographics actually match your target population
- Your sample size is large enough (typically 384+ responses for large populations)
- Your selection is random, not self-selected
- You're not systematically excluding entire groups
Social media data from API-limited tools fails on multiple counts. ⬇️
You've got self-selection bias – you only capture users on platforms you're monitoring. Miss TikTok? You've excluded everyone there.
You've got systematic exclusions – API limitations create predictable blind spots. You'll always miss Stories. You'll always lose data during rate limits.
You've got demographic distortion – platform biases stack up. Twitter skews male and tech-focused. Instagram skews young and visual. These biases compound.
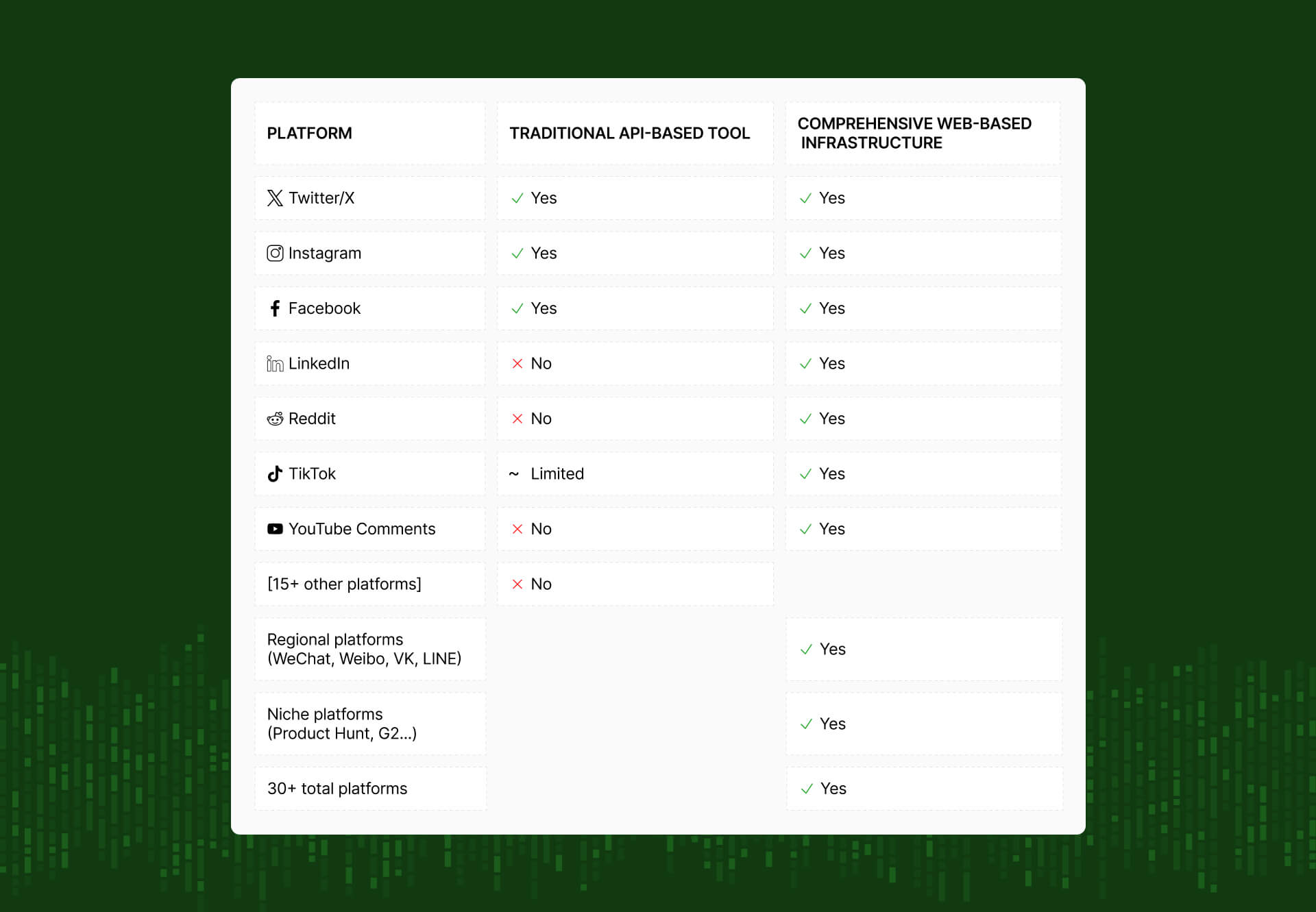
The three dimensions of data completeness
True completeness means you need coverage across three independent dimensions. Miss even one, and your data foundation crumbles.
Breadth of data
You capture all the relevant posts and conversations within your tracking parameters. Nothing gets filtered out by API limitations, rate limits, or sampling.
Historical data
When you want to look at past data, whether you're checking out a new competitor or analyzing historical trends, you can actually access it. If you start monitoring a competitor today, you should be able to see their mentions from six months ago.
Historical completeness lets you do things like:
- Research competitors you just discovered
- Run year-over-year trend analyses
- Study past crises to learn from them
- Establish baselines for new products or campaigns
Temporal data
Your data collection works consistently over time. When your product goes viral, you still capture every mention, not just what fits within API caps.
Traditional API-based monitoring gets worse when you need it most.
Normal, quiet days:
- 500-1,000 mentions per day
- API rate limits: Not hit
- Data completeness: 70-80%
Important, high-volume days (viral moments, crises, launches):
- 10,000-50,000 mentions per day
- API rate limits: Blown through within hours
- Data completeness: 20-40%
You get your best data when nothing important is happening. You get your worst data during events that matter.
What complete data enables
When you have truly complete data, you can do things that incomplete data simply can't support:
✔️ Statistically valid market research: Representative samples that support defensible strategic decisions, not just educated guesses dressed up with charts.
✔️ Real competitive intelligence: See competitor moves as they happen across all channels, not 30-60 days later when they finally show up in your limited monitoring.
✔️ Crisis detection instead of crisis response: Catch emerging issues at 50-100 mentions when you can still contain them, not at 5,000+ mentions when the damage is done.
✔️ True voice-of-customer insights: Product feedback from your actual customer base, not an oversampled vocal minority on Twitter.
Now let's get into exactly where your data is disappearing – and why you may not have been told about it.
Why You're Not Getting All The Data You Should Be
If you’re getting your social media data through APIs, your pipeline is incomplete by design – built into how platforms control data access through APIs.
Here are the three mechanisms that systematically exclude data from your reports, often without you knowing it's happening. ⬇️
API rate limits
Platform APIs cap how many data requests your tools can make per minute, hour, or day. When you hit that limit during a high-volume event, your tool just... stops collecting data. Without a warning, or an error message. It just stops.
According to X/Twitter's API documentation, even their paid Basic tier caps you at 10,000 tweets per month for the Tweet Cap limit.
Now here's the problem: a single trending hashtag can easily generate hundreds of thousands of tweets in just a few hours. Your monthly allowance can be gone before lunch.
Meta's Graph API for example puts rate limits in place to manage server load – understandable from their perspective, but it means your data collection slows to a crawl right when things get interesting.
⚠️ If you see suspiciously round numbers in your dashboard (exactly 1,000 or 5,000 mentions), you've likely hit an API cap or sampling limit. Real social media activity is messy: you'd expect to see 9,847 mentions, 11,234 mentions, numbers with natural variance.
Platform sampling
APIs don't just limit collection speed, they limit volume by returning samples instead of complete result sets. When query volume is high, platforms return a percentage of total matching results, not all results.
Meta's Graph API documentation acknowledges that "high-volume queries return sampled results", but doesn't specify what percentage or when sampling kicks in.
💡 Pro tip: Check your vendor's documentation for terms like "representative sample," "subset of results," or "up to X results" – these are red flags for sampling.
Historical access restrictions
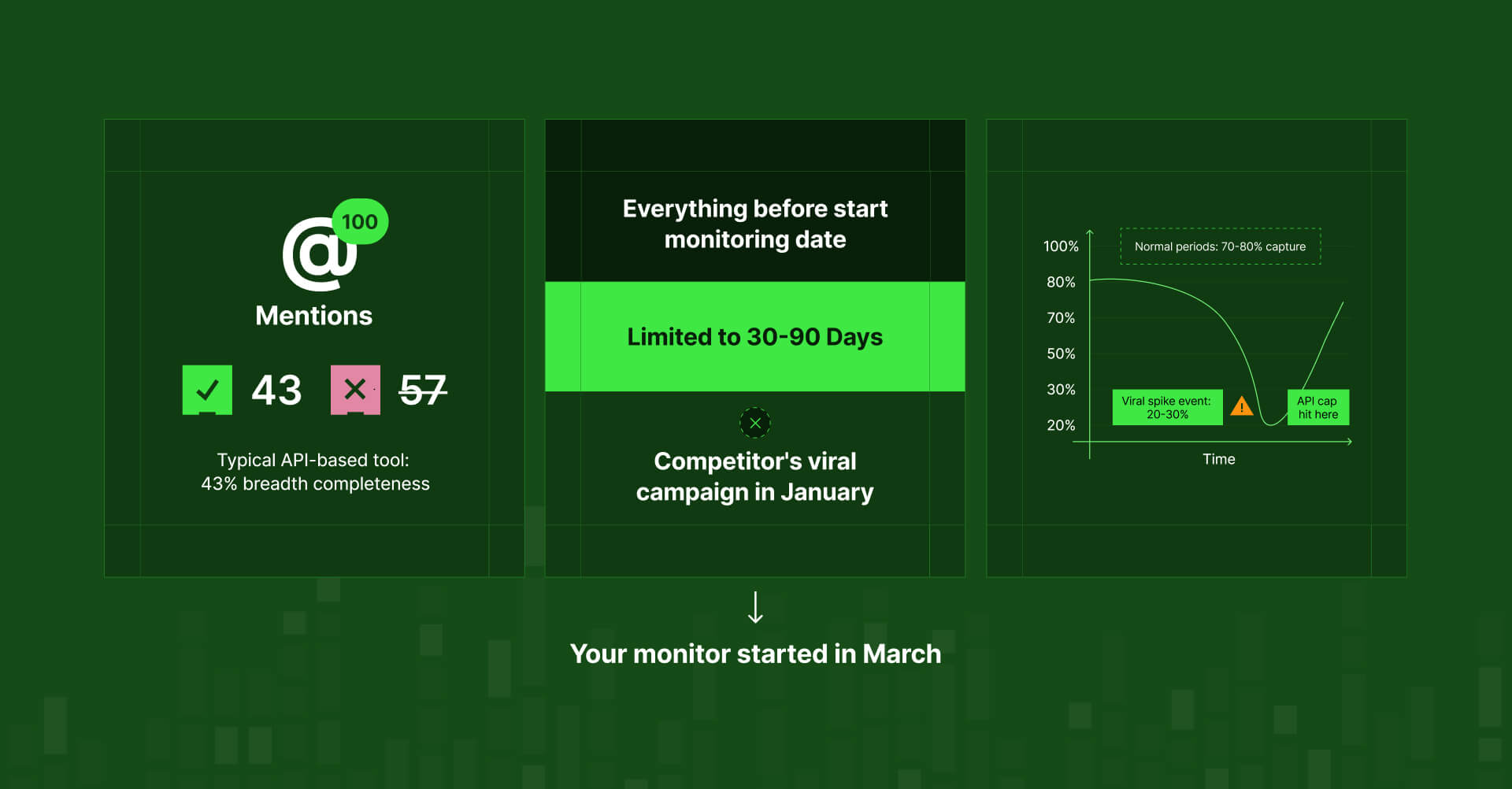
Most APIs only give you data from the moment you start tracking forward. Press "start" today? That's your Day Zero. Everything before that is gone.
Want to analyze historical trends? Benchmark against past campaigns? Research a competitor's history before you discovered them? Not possible.
According to Twitter's API pricing, here's what you get:
- Basic tier ($200/month): 30 days of historical search
- Enterprise tier: Full historical access at custom pricing (typically $42,000+/month)
Instagram's API has severe historical restrictions even on paid tiers. TikTok's API situation for historical data is even worse: their Research API offers very limited historical access, and that's only if you're approved for academic or research purposes.
What this means in practice
You start tracking a competitor in March. They had a brilliant campaign that went viral in January and completely shifted their market position. To you? That campaign doesn't exist. It's invisible. Your competitive intelligence starts the day you pressed "start", and everything before that is a complete blind spot.
This creates a systematic disadvantage: you have years of rich data on things you've been tracking forever. You have zero historical context on emerging threats, new competitors, or shifting trends you just noticed.
Content filtering
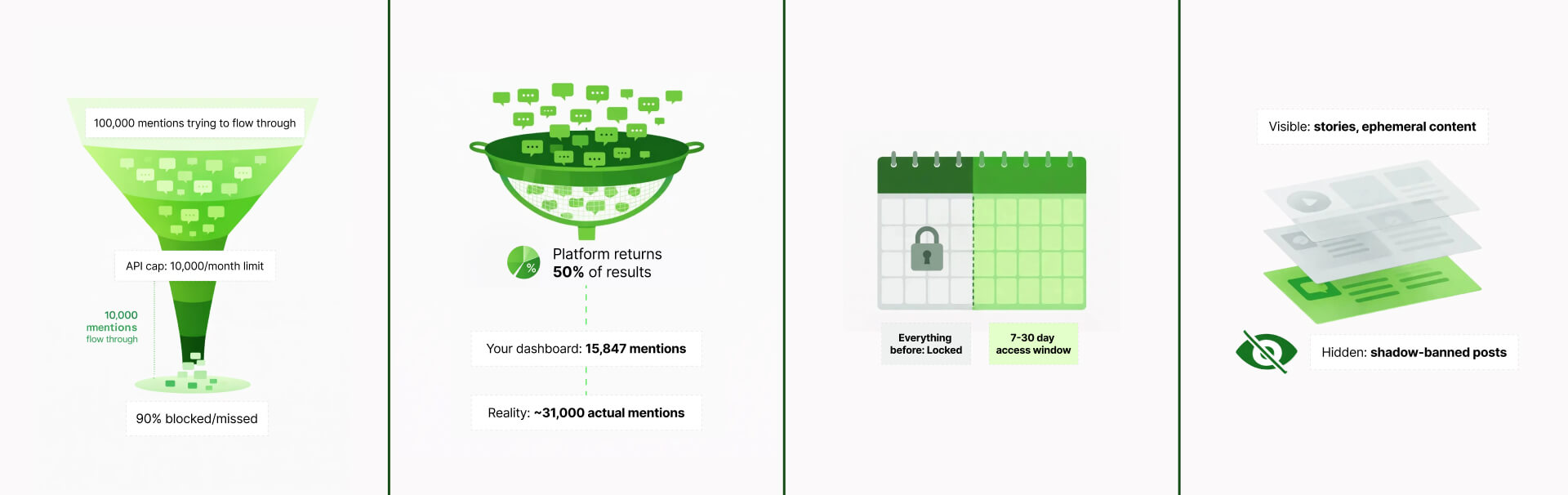
This is perhaps the most insidious limitation because you literally don't know what you're missing.
Platforms algorithmically filter what goes into API results based on criteria they don't publicize. Content gets excluded, and you never know it happened.
What gets filtered out?
- Shadow-banned posts (the user thinks it's live, but it's suppressed)
- Age-restricted content
- Certain types of private-but-technically-viewable content
- Stories and other ephemeral content
- Content flagged by moderation systems
Instagram Stories
The Instagram Stories blind spot in itself is massive. They reach over 500 million accounts daily. Stories are where a huge portion of authentic, unpolished customer reactions happen.
Stories are a significant content format on Instagram and Facebook, often generating higher engagement than feed posts. Yet most social listening tools have limited or no access to Stories data through official APIs, creating a systematic blind spot.
And the problem is, you don't know what you don't know. There's no notification that content was filtered out. Your analytics show "complete" data that's actually missing entire content categories.
The compounding effect
These three mechanisms systematically bias what you see. ⬇️
- Rate limits hit hardest during high-volume events – exactly when you need complete data most
- Sampling excludes more data as volume increases – your data gets less complete as conversations get more important
- Historical restrictions prevent retroactive analysis – you can't research past events or new competitors' histories
- Content filtering removes specific formats – Stories, ephemeral content, certain engagement types
You end up missing data systematically in ways that fundamentally change what you're measuring.
This begs the question, can you make accurate strategic decisions on data that's incomplete by design?
The Business Cost of Incomplete Data
Missing 60% of social conversations doesn't mean 60% less insight.
It means making million-dollar decisions based on fundamentally skewed data, then discovering the hard way that Twitter sentiment doesn't predict sales. ⬇️
When data doesn't match reality, decisions fail
According to statistical sampling principles, market research requires representative samples to produce valid conclusions. When your sample systematically overrepresents one demographic while underrepresenting others, your research is statistically biased – no matter how large the sample size.
If your social listening is 70% Twitter data, you're oversampling young, male, tech-focused users (Twitter's documented demographic per Statista).
If your actual customer base is 55% female, skews older, or isn't tech-industry focused, your "social sentiment" is measuring the wrong population.
- Strategies built on unrepresentative data optimize for the demographics you're oversampling, not your actual customers. You're essentially conducting market research on the wrong market.
- Product features get prioritized based on what young tech users want, not what your actual customers need.
- Marketing messages get crafted for audiences that don't represent your buyers.
- Competitive positioning gets based on conversations among demographics that aren't your target market.
More mentions from the same biased sample don't fix the fundamental issue: you're listening to the wrong people.
Product development optimizes for the wrong features
When product teams analyze incomplete social feedback, they optimize for the loudest voices on monitored platforms, not actual customer needs.
Twitter users might demand feature A (mobile-first, gamification, social sharing). Your actual customers (who don't post on Twitter) need feature B (reliability, integration, customer support).
Build based on incomplete data, and you've invested development resources solving problems your customers don't have while ignoring the ones they do.
Competitive intelligence operates on a delay
Forrester research on competitive intelligence found that companies relying on limited platform monitoring experience significant delays in detecting competitive moves.
When you monitor only 1-2 mainstream platforms, you see competitor activities after they've hit critical mass – not when they're emerging on platforms like Product Hunt, Bluesky, or TikTok where early adopters congregate.
By the time a competitor's strategy shows up in your Twitter monitoring, they've already:
- Launched on platforms you don't monitor
- Built early adoption momentum
- Secured partnerships and press coverage
- Captured market share
You're analyzing outcomes, not detecting opportunities.
Crisis response costs multiply
Crisis management operates on a simple principle: early detection enables containment. Late detection requires damage control.
When your monitoring misses the Tiktok post, Discord discussion, or niche forum where a crisis ignites, you don't detect it until it spreads to mainstream platforms.
By then, the conversation has amplified 10-100x, media has picked it up, and containment is no longer possible. You're in full crisis response mode, which costs exponentially more than early intervention.
Customer experience improvements miss the mark
When you analyze customer sentiment from incomplete data, you optimize for the wrong pain points.
- Twitter complaints are performative and public
- Reddit discussions are detailed and honest
Miss two of those three channels, and you're optimizing customer experience based on one specific type of feedback that doesn't represent actual customer priorities.
So how do you know if your social data is complete, or if you're making decisions on a skewed sample? ⬇️
How to Determine if Your Social Data is Complete
If you suspect your data is incomplete (and statistically, it probably is), here's how to assess the extent of the problem.
Completeness spot check
This simple audit helps you estimate how much social data your tool is actually capturing.
Step 1: Choose a high-volume event from the past week
Select something with clear, searchable parameters: branded hashtag, product mention, trending topic your brand participated in.
Step 2: Check your tool's reported volume
Note the total mentions/posts your social listening dashboard shows. Export if possible for later verification.
Step 3: Manually search each platform
Go directly to X, Instagram, TikTok, etc. Search the same hashtag or keyword.
- For Twitter/X: Use advanced search with date range limiting. If it shows "50+ tweets," multiply visible count by extrapolation factor
- For Instagram: Search hashtag and note "### posts" total count shown at top
- For TikTok: Search hashtag and count videos on first 3 pages (TikTok doesn't show total counts).
- For Reddit: Search across relevant subreddits – Reddit shows "### results" count.
Step 4: Calculate the gap
Your tool showed 500 mentions. Manual search suggests 1,200+ exist. That's a 58% data gap.
Step 5: Ask your vendor to explain
"Why didn't these 700 mentions appear in my dashboard?"
Questions to ask your data provider
When evaluating tools or auditing current vendors, ask these questions:
- "What percentage of total public social content matching my parameters does your tool capture?"
- "Do you use platform APIs or alternative collection methods?"
- "How do you handle API rate limits during high-volume events?"
🚩 Red flags in your dashboard
Source distribution pie chart
✅ Healthy distribution: No single source represents more than 25% of data, with diverse platform coverage across 6-8 platforms.
❌ Red flag: Twitter 73%, Reddit 18%, Facebook 9%: single source dominates, indicating skewed insights.
Geographic distribution
For global brands, data should roughly align with actual market distribution. If you operate globally but see North America 81%, Europe 14%, Other 5% – you have severe Western bias.
Language distribution
According to W3Techs, English represents 58.8% of websites but only 17.5% of the world population speaks English. If your "global" monitoring shows English 94%, Other 6%, you're missing massive conversation volume.
Missing platforms

Check:
- Is TikTok included?
- Reddit?
- YouTube comments?
- Industry-specific platforms like Stack Overflow for dev tools, G2 for B2B software?
If 2+ critical platforms are missing, you have major blind spots.
Suspiciously round numbers
Dashboard shows exactly 1,000 or 5,000 or 10,000 mentions? These are often API sampling caps. Natural results show variance: 9,847 mentions, 11,234 mentions.
Infrastructure Alternatives to Traditional APIs
If your audit reveals significant gaps, what's the alternative?
Why APIs weren't built for complete data access
Social platform APIs were originally designed for developers building features like post scheduling and account management – not data intelligence.
As the social listening market grew, platforms recognized competitive advantage in restricting data access.
Web-based data collection: how it works
If a human can see content by visiting a platform in their web browser, that content is publicly accessible.
You can open Twitter in your browser and see tweets. You can visit Instagram and see posts. You can browse Reddit threads. There’s no API required, you're just viewing public web pages.
Web-based data collection works on this same principle. Instead of asking platforms for data through their restricted APIs, you access the platforms directly through web browsers – the same way any person would.
The difference is that instead of a human manually browsing and copying information, automated browser technology does it at scale.
Web-based collection automates this exact process using headless browser technology: essentially browsers without the graphical interface that a human needs.
These automated browsers:
- Visit public URLs on social platforms
- Render JavaScript content (just like a regular browser)
- Extract visible information that's publicly available
- Do this systematically across 30+ platforms
- Scale to collect millions of data points
This only collects publicly accessible information. Content that any person could manually view by visiting the platform. It doesn't bypass authentication, access private accounts, or circumvent platform security.
The advantage
Web browsers give you what humans can see:
✔️ Complete results (what appears in search results)
✔️ No artificial rate limits
✔️ Full context including images, videos, formatting
✔️ Access to Stories and ephemeral content through web interfaces
When you visit Instagram in your browser, you can view Stories. The Instagram API doesn't provide Stories data at all. Web-based collection can access Stories because it's using the same web interface you use.
What to look for in headless social media data infrastructure
Not all web-based collection is created equal. When evaluating providers:
✔️ Platform breadth: Should cover 15-20+ platforms including regional platforms (WeChat, Weibo, VK) relevant to your markets
✔️ Ethical implementation: Respects platform terms, uses reasonable request rates that mimic human behavior, doesn't circumvent authentication
✔️ Legal defensibility: Clear documentation that collection is limited to publicly accessible data, understanding of relevant legal precedents
✔️ Data quality: Structured output that's clean, normalized, and integrates with your data systems
✔️ Reliability: Infrastructure that handles platform changes, maintains consistent collection, alerts when issues occur
💡 Pro tip: The best social data infrastructure is invisible to end users. Evaluate vendors on data completeness and reliability, not dashboard aesthetics. Your analytics team can build beautiful visualizations on top of complete data.
A hybrid reality
In practice, the most effective social media data solutions often use a hybrid approach:
- APIs where they work well: Some platforms (like Reddit) have relatively open APIs with fewer restrictions. Use the API for reliability and efficiency.
- Web-based collection where APIs fail: For platforms with restrictive APIs (Twitter, TikTok) or content APIs exclude (Instagram Stories), web-based collection fills the gaps.
- Multiple methods for critical platforms: Cross-validate data from both sources for completeness and accuracy.
The goal isn't to avoid APIs entirely, it's to not be limited by API restrictions when those restrictions prevent complete data access.
Final Thoughts
Most social listening content focuses on how to analyze data. This article asked a more fundamental question: What are you actually analyzing?
- Social data is not one platform. Conversations happen across 30+ platforms. Monitor 1-2 and you're not getting "most" of social media, you're getting an overlapping demographic slice.
- Social data is not one demographic. One platform equals one bias. Your data skews toward whichever platform dominates your monitoring.
- Social data is not one language, one country, or one algorithm. Global brands making decisions on English-only, US-centric data are flying blind in most of their markets.
- Real insight requires diversity of sources, geographies, and voices. You cannot understand social media sentiment by listening to a narrow demographic slice on 1-2 platforms.
- Social listening fails before analysis begins if the data foundation is incomplete. Dashboards don't fix blind spots. Better queries don't fix missing sources. You can’t analyze data you never collected.
If you're trying to understand customers across demographics but monitoring platforms that skew to one demographic, you're making decisions based on a skewed picture.
See what complete social media data – across 30+ platforms, with true demographic diversity, without API limitations – reveals about your market. Book a demo with Datashake to audit your current data completeness and explore how comprehensive infrastructure eliminates the gaps traditional tools can't solve.



More insights you might like


