What is Headless Social Listening? (And Why Your Dashboards Could Be Way More Insightful)

If you’ve ever evaluated social listening tools, you’ve probably spent 90% of that time comparing dashboards & reports – the colors, the charts, the UX.
But you’re optimizing for the wrong thing.
Picture two companies monitoring the same brand topic. Company A has a beautifully designed Brandwatch dashboard – color-coded sentiment charts, share-of-voice graphs, emotion breakdowns. Company B has raw JSON flowing directly into their Snowflake warehouse, feeding their BI stack, training their AI model.
Neither company has a better dashboard. But one of them owns their data. The other is renting a limited view of it.
The entire social listening industry has been built around the dashboard. When you evaluate tools, you look at the dashboards. When you buy, you're buying the dashboard experience. The data underneath (the actual asset) is treated as the means to the dashboard, not the other way around.
What if it's the other way around? What if the data is the product, and the dashboard is just one possible output – and maybe not even the most valuable one?
That's the idea behind headless social listening. It's a pattern that's already transformed content management, e-commerce, and analytics engineering – and it's starting to arrive in social intelligence. ⬇️
This post is worth reading if:
This approach is worth understanding if any of these sound familiar:
- You're evaluating social listening tools and not sure what to actually look for beyond the dashboard
- You use a social listening tool but feel like you're not getting the full picture
- Your team is using AI and realising your current data setup wasn't built for it
- You work with social data in any capacity and wonder why it lives separately from everything else your organisation tracks
- Someone on your team has already asked: "can't we just get the raw data?"

What Headless Social Listening Means
Headless social listening separates the data layer from the visualization layer. Instead of data living inside a vendor's dashboard, it's delivered via API to your own systems – a warehouse, a BI tool, an AI model. You own the data. You decide what to build on top of it.
"Headless" architecture separates the frontend presentation layer – the "head," meaning the UI, the screens, the charts – from the backend data infrastructure.
In a traditional monolithic tool, the two are fused. The data lives inside the vendor's system, and you can only access it through the interface they built.
In a headless architecture, the data layer operates independently. It lives in infrastructure you control, and you can attach whatever "head" you want to it: a dashboard, a BI tool, a data warehouse, an AI pipeline, a custom application.
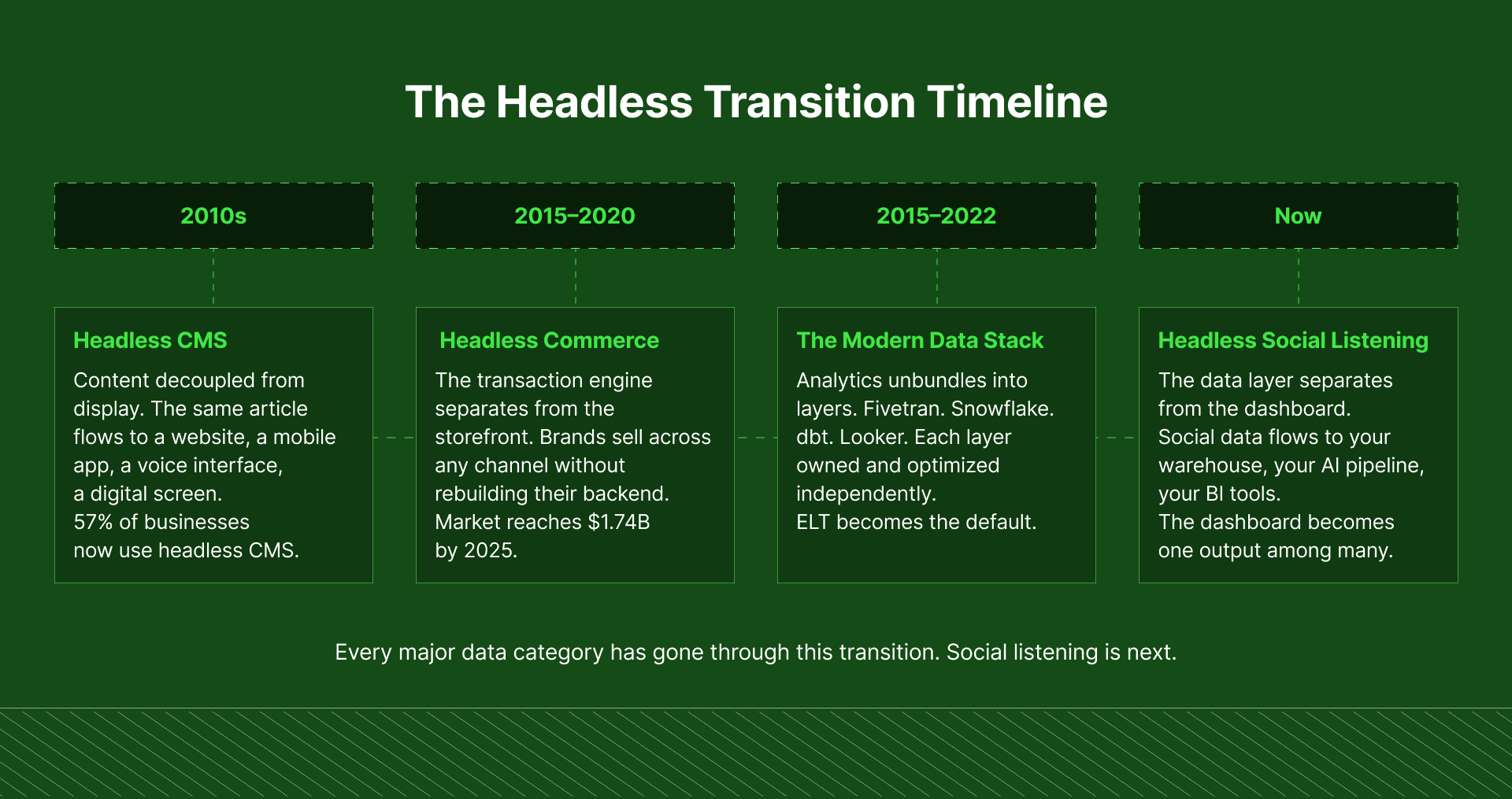
This architecture has swept through every adjacent technology category in the past decade ⬇️
Headless CMS
Traditional content management systems like WordPress bundled content storage and content display together. You managed everything in one place – which was fine, until you needed the same content to appear on a mobile app, a voice assistant, a digital screen in a retail store, or a smart TV interface. The monolith simply couldn't follow.
Headless CMS solved this by storing content in a backend repository and pushing it out to any frontend via API. Same content, different architecture, completely different range of possibilities.
Today, 57% of businesses are already using a headless approach, with 98% of the remaining companies planning to evaluate it: meaning what started as an experimental architectural choice is now the default for any content infrastructure built to last.
You probably already see this pattern in your own stack. SEO teams have been doing a version of this for years: exporting keyword rankings, backlink data, and search visibility from tools like Ahrefs or SEMrush into their own data warehouses, combining it with conversion data, revenue attribution, and product analytics to build custom dashboards their SEO platform was never designed to produce. The tool provides the data. The team owns the analysis. Social listening is simply the next category where that same logic applies.
Headless commerce
Traditional e-commerce platforms were designed to run one thing: a store. When brands needed to sell across channels – social commerce, in-app purchases, physical retail integrations – the store-centric monolith couldn't adapt.
Headless commerce separated the transaction engine from the customer experience layer, unlocking a flexibility that store-first platforms couldn't offer.
👀 The market has noticed: headless commerce is valued at $1.74 billion in 2025 and projected to reach $7.16 billion by 2032, growing faster than e-commerce as a whole. 74% of companies currently on blended SaaS commerce platforms are already moving toward fully headless approaches.

The modern data stack was already headless
The entire analytics engineering movement of the last decade was a headless movement in everything but name.
Rather than buying one all-in-one platform that ingested, stored, transformed, and displayed data, companies started unbundling the layers.
- Fivetran for ingestion
- Snowflake or BigQuery for storage
- dbt for transformation
- Looker or Power BI for visualization.
Each layer owned independently and optimized on its own terms. The shift to ELT (extract first, load and transform later) fundamentally changed how fast organizations could move with their data.
Every one of these shifts followed the same arc. Monolithic all-in-one tools work well at small scale and low complexity. But when requirements grow – more diverse, more specialized, more woven into broader workflows the original designers never anticipated – the monolith stops being a convenience and starts being a cage.
Where social data fits
Social listening is at that inflection point now. You're no longer just monitoring brand mentions. You're trying to join social signals to business outcomes, train AI models on real consumer language, build custom metrics your specific industry actually needs, and feed intelligence into workflows that live far outside the dashboard. The monolith wasn't built for that. It can't follow you there. ⚠️
One counterargument worth acknowledging: the broader data stack has seen a consolidation wave since about 2022. The "best-of-breed always beats monoliths" thesis that used to dominate has partially reversed: integrated social listening platforms are winning back some categories where tool sprawl got out of hand.
Why not all unbundling is created equal
But the lesson from that consolidation is nuanced. Unbundling doesn't work in every context, it works when the layers you're separating are genuinely different kinds of work.
Specifically: when they change at different speeds, serve different people, and require different expertise to maintain. If those conditions aren't met, you end up with fragmentation for its own sake. But if they are met, separating the layers creates more value than keeping them bundled.
Social data collection and visualization meet every one of those conditions.
Collection is ongoing infrastructure work. It means:
- Managing API relationships with a dozen social media platforms
- Absorbing changes when those platforms update their terms
- Normalizing wildly different data formats into something consistent
- And keeping the whole pipeline running reliably
It's engineering work. It compounds over time. It needs to be owned by people who treat it as infrastructure.
These tasks operate on completely different timescales, require completely different skills, and serve completely different people. Bundling them together doesn't make either one better, it just means the infrastructure decisions get made by whoever designed the dashboard, and the visualization decisions get made by whoever manages the API.
Separate the layers, and both improve.
The appetite for data ownership is already there
The pull toward owning social data is visible in the market right now, before "headless social listening" even existed as a named category ⬇️
- By 2023, 26.5% of brands were already considering developing in-house social listening technologies: a jump of more than 20% compared to 2019.
- 21.4% of social listening practitioners now work in dedicated in-house intelligence teams.
These companies just kept running into the same ceiling, and eventually decided they needed to build past it.
The AI pressure point
The most significant accelerant right now is AI adoption. The 2025 State of Social Listening survey found that 91% of social intelligence practitioners are already using generative AI in their work in some way.
The same survey highlights what practitioners most want to unlock: deeper consumer insights that blend social data with other data types – revenue, CRM, product analytics, search behaviour. That kind of blending is only possible outside a closed platform. You can't join tables that live in different vendor systems.
➡️ The moment your analysts are using AI to work with social data, they need that data in a format AI can actually consume.
❌ Exporting a sentiment chart and pasting it into ChatGPT is a workaround
✅Raw structured data in a warehouse, joined to everything else, feeding an AI pipeline – that's infrastructure
These aren't the same thing at all – one scales across your organization and compounds in value over time, the other breaks the moment anyone asks a question you didn't think to export for.
The last data silo standing
The enterprise data management landscape is shifting decisively from application-centric architecture toward a data-centric approach – one where data retains its meaning and context regardless of which tool it happens to be sitting in.
- ➡️Sales data flows to Snowflake
- ➡️Marketing data flows to Snowflake
- ➡️Product analytics flows to Snowflake
- ❌ Social data sits in a vendor dashboard, walled off from the rest.
In a data strategy conversation, that inconsistency is getting harder and harder to defend.
When All-in-One Social Listening Platforms Can Be the Right Choice
The major social listening platforms aren't bad products. They've invested heavily in what they do, they solve real problems, and for plenty of organizations they're absolutely the right tool for the job. 🙌
When they're the right choice
All-in-one platforms make sense when:
- Your team is new to social listening and needs structure and guidance to get started
- You want to test the waters before committing to a more serious data infrastructure investment
- You want sentiment analysis, trend detection, and emotion tracking that works immediately, out of the box
- Your analysts need a working interface right now, not a data feed to build infrastructure on
- Your use cases are standard: brand monitoring, campaign tracking, competitive share of voice
- You don't have the human resources to manage an in-house approach, and don't plan to build that capacity in the near term
If that's your situation, an all-in-one platform could be a great tool. But be mindful of not staying in it when your needs have grown past it because the dashboard still looks good and switching feels hard.

When the architecture becomes the ceiling
Enterprise users across the major social listening platforms consistently report hitting limits on bulk data exports – likely tied to underlying data licensing agreements. Direct integrations with visualization tools like Tableau or Power BI are limited; reviewers frequently end up on manual export workflows they'd rather not be on.
And when you do export, what you get is often a shadow of the actual data. Most platforms strip out the content itself (the raw text of the mention, the post, the comment) and deliver only metadata: author name, date, source, sentiment score. The engagement signals that matter most (likes, shares, replies, view counts) are frequently absent or aggregated beyond usefulness. You're handed a receipt for the conversation, not the conversation itself.
More significantly: all the major social listening platforms all gate API access behind enterprise plans that user reports place at roughly $8,000/year at the low end, with most paying considerably more. And since these companies don't primarily focus on API services, teams looking to push data extensively into their own systems often find the fit isn't really there.
The deepest limitation is the underlying design intent. These tools were built to be the destination for social data, not a waypoint you pass through on the way to somewhere else. Getting data out to train an AI model, join it to your warehouse, build custom analytics on top of it: that's a workaround inside a system that wasn't designed for it. ⚠️

The ambition gap
The 2025 State of Social Listening captured this tension: social intelligence professionals say they want to be more strategic – to extract deeper consumer insights – but they're stuck doing tactical work: competitive benchmarking and sentiment reporting. The tools are shaping the work, rather than the other way around.
When the ceiling of what a tool can show becomes the ceiling of what your team thinks to ask, the tool has stopped working for you.
Headless Social Listening Counters a Deep Problem: Social Media Platform Dependency
There's a specific risk with monolithic social listening tools that rarely gets discussed openly: the entire data supply chain runs through the platform's API relationships. When those change (often without warning, sometimes dramatically) your access to data changes with it.
Why data infrastructure handles this differently
This is the hidden fragility of all-in-one social listening tools. Their data supply chain is only as stable as their social media platform API relationships – which they don't control. When a social media platform changes its terms, restricts data fields, raises prices, or tightens rate limits, every tool dependent on that API has to absorb the cost or pass it downstream. Usually, the result is less data, higher prices, or capabilities that quietly degrade.
A dedicated data infrastructure layer is structurally better positioned to weather this. Rather than a single pathway through one platform's official API, it can maintain multiple access pathways to the same underlying data – normalizing the output so disruptions stay in the infrastructure layer and don't reach the analyst.
The all-in-one tool is a single point of failure. The data infrastructure layer is built with resilience in mind.
Worth knowing before you read on: Platform dependency is one way your social data gets compromised. But even on a quiet day with no API drama, most tools are already missing the majority of conversations happening across 30+ platforms. We broke down exactly where the data disappears →
What You Can Achieve With Headless Social Listening
When you decouple data collection from visualization, the use cases expand well beyond what any dashboard can offer. These are things that require raw, structured data access and simply cannot be built inside a closed platform.
1. Feed your own AI models with your own training data
This is the fastest-growing use case right now, and probably the most strategically significant.
LLMs are being applied across industries to analyze social media posts, reviews, and user-generated content — gauging public opinion, tracking trends, surfacing insights at scale.
But you can't train a model on data that lives inside a vendor's dashboard. You need the raw text, the metadata, the engagement signals, the author context. All in formats a training pipeline can actually use.
Fine-tuning on domain-specific data is accelerating because it delivers the kind of accuracy and compliance that generic models can't match at scale. Social data (real language, reactions, and patterns from real people) is one of the richest sources of domain signal a company has access to. But only if it owns it. Locked in a dashboard, it's a chart. In your own infrastructure, it's a training asset. 🤷
2. Connecting social signals to actual business outcomes
Inside a social listening dashboard, your social data exists in isolation. The tool can tell you brand sentiment is declining. It can't tell you whether that correlates with customer churn, whether it's concentrated in a specific product line, or whether it's regional.
Modern cloud warehouses (Snowflake, BigQuery, Databricks) are explicitly built to be unified analytical surfaces, capable of handling the volume and variability of data coming from social platforms, customer transactions, IoT devices, and more.
➡️ Social data should flow into this infrastructure alongside CRM records, sales data, NPS scores, and product analytics – because that's where the insights that actually drive decisions live. The pattern that social sentiment in a specific region predicts churn from that region is only visible when those datasets are joined. Closed platforms make that invisible.
3. Build industry-specific metrics that don't exist out of the box
Generic tools are built for a generic customer. Every industry has metrics that matter to them specifically. ⬇️
A pharmaceutical company tracking adverse event signals needs different filters, different source coverage, and different alert thresholds than a consumer brand tracking a product launch. A financial services firm doing compliance monitoring needs fundamentally different data architecture than a fashion brand analyzing influencer sentiment.
4. Work in your own tools
Enterprise analytics teams now work across an average of 400 data sources, with more than 70% relying on five to seven different tools just to get through daily workflows. Adding a separate social listening platform with its own interface, its own export quirks, its own data model, and its own login doesn't make this better. It makes it more fragmented.
When social data flows into Snowflake or BigQuery alongside everything else, analysts can query it in SQL, transform it in dbt, and visualize it in Looker or Power BI – the same environment they use for every other data source. Social data stops being a silo. It becomes part of the analytical fabric of the organization.
5. Historical data and archive access on your terms
One of the more discrete advantages of owning data is temporal. All-in-one tools store historical data on their infrastructure, with their retention policies, accessible only through their interfaces. Downgrade your plan and your historical depth shrinks. Switch social listening platforms and you lose continuity. That's their data, hosted on their terms.
When raw social data lives in your own warehouse, you set the retention policy. Three years of data queries the same as three months – without tiering, add-ons, or waiting for a vendor's query engine to process your retrospective analysis. The data is just there, like any other table.
6. Blending social data with every other signal your business tracks
Inside a social listening dashboard, social data exists in its own world. It can tell you sentiment is declining. It can't tell you whether that decline is showing up in your churn numbers, whether it's concentrated among a specific customer segment, or whether it started before or after a product change.
The insight that actually drives a decision – social sentiment in this region is predictive of churn from that region – is only visible when the datasets are joined. And that join can only happen outside a closed platform.
When social data flows into your warehouse alongside CRM records, product analytics, sales data, NPS scores, and search behaviour, an entirely new category of question becomes answerable:
- Does negative sentiment about a specific feature correlate with trial-to-paid conversion drop-off?
- Which customer segments are generating the most negative social signal – and do they overlap with your highest-value accounts?
- Is there a lag between social sentiment shifts and revenue impact – and if so, how long?
- Which topics trending on social are already showing up in support tickets, before they hit the mainstream?
None of these questions can be answered inside a social listening tool. All of them can be answered when social data lives in the same infrastructure as everything else.
Owning your social data layer doesn't just improve what you can do with social data. It improves what you can do with all your data.
7. The fastest way to feel the difference: a practical test
Here's the lowest-friction way to feel the gap firsthand. ⬇️
Take a topic you're currently monitoring. Export every mention for a given month from whatever tool you use, and note what the built-in analytics surface — sentiment scores, volume trends, flagged topics.
Then upload the same raw mentions to ChatGPT or Claude and ask: "What can you learn from this data beyond what a standard social listening dashboard would show?"
Pay attention to what comes back. The recurring phrases that don't match your current keyword setup. The timing patterns the charts didn't catch. The unexpected correlations in author type or geography. That gap, between what the dashboard showed you and what the AI finds in the raw text, is what headless social listening makes available as a baseline.
Not sure if your social data is actually representative? We built a 5-step audit framework that walks you through source distribution, data depth, metadata quality, and historical reach. Read the guide →
Looking Ahead – Will Enterprise Social Listening Unbundle?
The social listening market is going through a consolidation wave.
- Hootsuite acquired Talkwalker in 2024
- Meltwater went private in a €570 million deal
- Generative AI has become the main competitive battleground, with vendors racing to embed proprietary LLMs into their analytics layers.
What none of this changes is the underlying data architecture. All-in-one vendors are competing on surface features (smarter dashboards, better AI summaries, cleaner UI) while the fundamental question of who owns the data, and who can do what with it, remains unchanged. They're making the dashboard smarter. They're not making the data more accessible.
The broader market is already moving
The parallel from adjacent categories is worth watching. 👀
SaaS products that once built proprietary internal analytics are increasingly moving their data into the modern data ecosystem instead: syncing to warehouses via APIs rather than locking everything inside their own interface.
➡️ Salesforce, once fiercely protective of the data inside its CRM, now partners with Snowflake. The expectation that enterprise software should deliver data to the warehouse rather than trap it inside a proprietary interface is becoming the standard.
Social listening is late to this shift. But the direction is clear. 🫡
How to Get Started With Headless Social Listening
The dominant pattern in data team build-vs-buy decisions is "buy-first, build when necessary”. Teams want vendor speed and stability as a foundation, and bring things in-house when specific gaps make it necessary.
The right posture for most organizations isn't "replace the social listening tool immediately." It's a staged transition that builds internal evidence while continuing to deliver value. ⬇️
Stage 1: Run the diagnosis test (zero investment required)
Export your full dataset for a topic you care about. Note every metric and insight your current tool surfaces. Upload those same raw mentions to ChatGPT or Claude and ask: "What can you learn from this data beyond what a standard social listening dashboard would show?"
The gap between what the tool gave you and what the AI surfaces from the same raw data: that's your internal business case. Write it down.

Stage 2: Establish the data flow without changing anything else
If your organization has a cloud data warehouse, start getting social data flowing into it alongside your other sources. Don't change your analytics process. Don't retire the current dashboard. Just establish the pipeline: raw social data in a queryable format, sitting next to the customer, product, and market data you already have.
Think of this as a data engineering project, not a social listening project.
Stage 3: Build one metric your current tool can't produce
Work with a social or market analyst to identify one business-specific metric your platform can't calculate.
- A cross-source correlation
- A custom segmentation filter
- A number that joins social sentiment to a business outcome.
Build it. Show the result to leadership. That becomes the proof point for expanding the infrastructure.
Stage 4: Move visualization to tools you already own
With data in your warehouse and custom logic validated, build dashboards in Looker, Power BI, or Tableau – pulling from data you own, with metrics you defined.
The dashboard still exists. It just belongs to you now.
⚠️ This isn't right for everyone
Headless social listening is not the right choice for every organization. It requires:
- A data team with engineering capability, or the budget to build one
- An existing data infrastructure to integrate into (a warehouse, a BI layer)
- Analytical ambitions that go beyond what the major platforms offer out of the box
- A tolerance for the time required to build custom analytics on top of raw data
If your organization doesn't have these, a structured all-in-one platform may be a good choice for now.
The Dashboard Isn’t The Differentiator – The Data Is
Every organization running social listening is asking some version of the same question: what are people saying about us, and what does it mean?
All-in-one tools answer that with a dashboard.
Headless social listening answers a harder, more valuable question: what does the data tell us that we didn't know to ask?
That difference compounds.
✅ Organizations that own their social data can run analyses they haven't designed yet, join it to datasets that don't exist yet, feed it into models that aren't built yet.
❌ Organizations renting a view through a vendor dashboard can only see what that vendor decided to show them – today, and every day they stay inside the platform.
The dashboard was never the differentiator. It was always the data. The only question is whether you own it, or whether you're just visiting.
Ready to see what your current setup is missing? Book a demo — we'll walk through your specific use case and show you what comprehensive, representative social data looks like.



More insights you might like


%20thumbnail.jpg)