GDPR and Social Media Data: A Compliance Guide for SaaS Teams

Does GDPR apply to publicly available social media data? Yes, when it’s built correctly. GDPR applies to public social data, but that doesn’t make it off-limits. It means the collection needs a lawful basis, the data needs to be handled responsibly, and both your provider and your team have specific roles to play.
If you’re building a product on social or review data, or evaluating an API provider to power that product, you’ve probably wondered: how does GDPR actually apply, and what does that mean for us?
The short answer is: yes, GDPR applies, even to publicly available data. But that doesn’t mean social data is legally fraught or off-limits. It means the way you collect, use, and manage that data needs to be structured correctly.
This guide covers what GDPR actually requires for social and review data, where your obligations sit versus your provider’s, what the enforcement cases genuinely tell us about risk, and what good practice looks like for a product team.
Who this applies to
GDPR applies to any organisation that processes personal data of EU residents, regardless of where that organisation is based. If your product uses social or review data that can identify a person in the EU or UK, the regulation applies to that data.
That extraterritorial scope catches a lot of US-based teams off guard. Being incorporated in the US and running US servers doesn’t create a safe harbour if the people in your data are based in Europe.

GDPR has no borders. A US company processing data about EU residents must comply. A UK company post-Brexit must comply with UK GDPR. The common thread: if your data includes people in Europe, the regulation is live for that data.
Where the responsibility sits: your team vs. your provider
In GDPR terms, you’re the data controller: you decide what data to use, what use cases to build, and what to do with it downstream.
Your API provider is a data processor: they collect and deliver data on your behalf. The controller carries primary accountability, but a good provider reduces the work significantly by handling the collection layer correctly.

The biggest misconception: public ≠ free to use
There’s a confusing assumption in this space: if someone posted publicly, anyone can use it. It feels logical. But under GDPR, it’s not how the law works.
Public availability isn’t a legal basis. Twelve global privacy regulators confirmed this in a 2023 joint statement (later expanded to 16 authorities) stating that publicly accessible personal data is still subject to data protection law. The Dutch DPA has said explicitly that scraping social media data “almost always involves personal data.” Public or not.
What global regulators say about scraping public social media data
The test regulators actually apply isn’t ❌ “was the data accessible?” It’s closer to: ✔️ “could the person who posted this have reasonably expected it to be used in this way?”
That’s the contextual integrity principle, the idea that appropriate data use is shaped by the norms of the context in which it was shared.
A GDPR test for determining what is "publicly available"
The question is not: “was the data publicly accessible?”, the question is: “could the person who posted this reasonably expect it to be used in this way?”
That’s where most social data use cases run into compliance problems. The principle of contextual integrity (used by both privacy scholars and increasingly by regulators) says that appropriate data use is governed by the norms of the context where it was originally shared:
Someone posts their job title on LinkedIn. They reasonably expect to be contacted by relevant professional connections. → They do not reasonably expect their data to be scraped, aggregated into a database of 160 million contacts, and sold for mass outreach. Even though the data was “public”.
This is what got KASPR fined €240,000 by France’s CNIL in December 2024.
➡️ The reason this matters for your product decisions: the use case is as important as the data itself. Aggregating public review signals for market intelligence is a fundamentally different activity from harvesting personal contact data for outreach.
The data may look similar at the collection level, but the purpose, the downstream use, and the reasonable expectations of the individuals involved are completely different, and that difference is what regulators assess.
What counts as personal data in social and review data
GDPR’s definition of personal data is intentionally broad: any information that identifies, or could help identify, a living natural person.
Before integrating any social or review data feed, map what you’re actually collecting against GDPR’s definition.

The key point: you don’t need a name in the data for it to be personal data ⬇️
- A username that consistently identifies one person across platforms qualifies
- A review attached to a traceable account qualifies
- A combination of a timestamp and a location signal that narrows someone’s identity qualifies
Special category data in social feeds: a hidden compliance risk
Article 9 special categories – health, political opinions, religious beliefs, sexual orientation, biometric data – come up in social data more than teams expect. In a pharma review mentioning a condition, a Reddit post in a political forum, or a tweet about someone’s health experience.
The saving grace for most market intelligence use cases is a specific exception: data that someone has manifestly made public themselves can be processed under relaxed conditions. But “relaxed” doesn’t mean unrestricted. You still need a valid Article 6 lawful basis. And purpose limitation applies just as it does for any other data: the fact that someone disclosed a health condition publicly doesn’t mean you can use that data to make automated underwriting decisions.
The only realistic legal basis: Legitimate Interest
GDPR Article 6 lists six possible lawful bases. For social and review data collected from third-party sources, five of them almost never apply. You can’t get consent from millions of people whose posts you’re collecting. You have no contract with them. There’s no legal obligation at play.

What the Legitimate Interest Assessment (LIA) requires
Legitimate Interest is the mechanism GDPR provides for proportionate, responsible data use that doesn’t require a direct relationship with each individual. It’s the intended framework for exactly this kind of processing.
The EDPB’s October 2024 guidelines and France’s CNIL June 2025 scraping guidance both confirm it’s the appropriate basis for social data collection – provided you document a three-part Legitimate Interest Assessment (LIA).
Before you process, you must document all three parts:
- The purpose test: identify a specific, clear, and real legitimate interest. “For marketing” or “for our product” won’t hold up. You need documented specificity: e.g. “identifying adverse event signals in pharmaceutical review data to improve product safety monitoring.”
- The necessity test: prove that processing personal data is genuinely necessary to achieve your purpose. If you can get the same insight from anonymised aggregates, the necessity test fails.
- The balancing test: weigh your interest against the fundamental rights and freedoms of the individuals whose data you’re processing. Key factors: their reasonable expectations when they posted, the sensitivity of the data, and the potential impact on them if misused.
ℹ️ Your LIA vs. your provider’s LIA: These are two different documents covering two different activities. Your provider’s LIA covers their data collection. Yours covers what you do with that data in your product. Both need to exist. The good news: a provider who’s done their compliance work will help you understand what needs to go into yours.
Enforcement in practice: how regulators are responding
The regulatory climate has changed significantly in the past few years. These are the precedents for teams building on social and review data.

Each case follows the same pattern: personal data collected or transferred in ways that the people involved could not reasonably have anticipated, with inadequate infrastructure to honour their rights.
- KASPR harvested contact details for outreach from profiles users had restricted
- Clearview built biometric identification systems from photos shared in entirely different contexts
- TikTok routed personal data through a jurisdiction with no protection framework.
None of these cases involve social intelligence, review aggregation, sentiment analysis, or competitive market research: the use cases that a social data API like Datashake is built for.
The compliance requirements are the same across all of these, but the nature of the use case changes the risk profile substantially. Aggregate insights from public reviews and social conversations sits in a fundamentally different place from individual profiling and contact harvesting.
The KASPR case in detail and why it matters for your product
KASPR built a Chrome extension that let customers extract professional contact details from LinkedIn profiles. Their database held approximately 160 million contacts. CNIL’s December 2024 ruling identified four failures:
- Unlawful collection: scraping contact details from users who had expressly restricted their profile visibility to first and second-degree connections
- Disproportionate retention: storing data for five years, with the clock resetting every time a person changed jobs – effectively indefinite
- No transparency: data subjects weren’t informed for four years, and when they were, the notice was only in English
The broader enforcement environment
European data protection authorities issued approximately €1.2 billion in GDPR fines in 2025, with the total since 2018 now exceeding €7 billion.
The EDPB’s 2026 Coordinated Enforcement Framework is focused on transparency and information obligations – how organisations document and communicate what they’re doing with people’s data.
That’s directly relevant to the documentation your provider should have in place, and that you should review before signing a contract.
Defining your use case: purpose limitation and data minimisation
With the right provider in place and a signed DPA, the most important thing your team needs to do is define your use case properly before you build.
This is what purpose limitation requires, and it’s also what makes your Legitimate Interest Assessment hold up.
Purpose limitation: decide before you build
GDPR requires that data be collected for specified, explicit, and legitimate purposes, and that it isn’t repurposed without reassessment.
In practice, this means deciding what you’re using the data for before the integration is built ⬇️
- Be specific: “Sentiment analysis of G2 and Trustpilot reviews to track competitive positioning for our sales team” is a valid stated purpose. “Review data for our product” isn’t.
- Document it: your Records of Processing Activities (ROPA) needs to capture each use case, the data types involved, the lawful basis, the retention period, and where the data flows to
- Reassess when you expand: if a new feature uses existing social data in a meaningfully different way, it’s worth a quick reassessment. Ask yourself: would the people whose data you’re using expect this new use?
Data minimisation: the simplest risk reduction you have
Under Article 5(1)(c), you should only hold data that’s adequate, relevant, and necessary for your stated purpose. In social data terms, that’s usually common sense:
- Use aggregate signals rather than full user profiles where aggregate data serves your purpose
- Keep trend-level data rather than post-level data if individual posts aren’t what your product needs
- Don’t collect Article 9 fields your product has no specific use for
Less personal data in your system means fewer erasure obligations to work through, a smaller surface area in any breach response, and a cleaner audit trail when a procurement team asks about your data handling. It’s the most practical form of risk reduction available without changing anything about what your product does.
The right to erasure: not just a policy question
Erasure is the area where the gap between a written privacy policy and an actual working system tends to be most visible.
Having a policy that says “we honour erasure requests” is not the same as having a system that can find and delete a specific individual’s data cleanly across every layer.
The EDPB named the right to erasure as the 2025 Coordinated Enforcement Framework priority across 32 European data protection authorities.
➡️ Under Article 17, individuals can request deletion when their data is no longer necessary for the original purpose, when they object to processing, or when the processing was unlawful. You have 30 days to respond.

Design for it now: Erasure support is much harder to retrofit onto a system that wasn’t designed with it in mind. How you index and store social data needs to account for the ability to find and delete records by individual. If you can’t do that cleanly today, it’s worth addressing before the first request arrives.
What this means when you’re building a SaaS product on social data
You’re not a passive consumer of data. When you integrate social or review data into a product that touches EU residents, you take on GDPR obligations as a data controller or processor, and often both.
Controller vs. processor: what’s the difference and why it matters

The US/EU legal divide: why your vendor’s country of origin matters
If you’re buying data from a US-based provider, or your product is US-based with EU users, this gap has real compliance consequences.
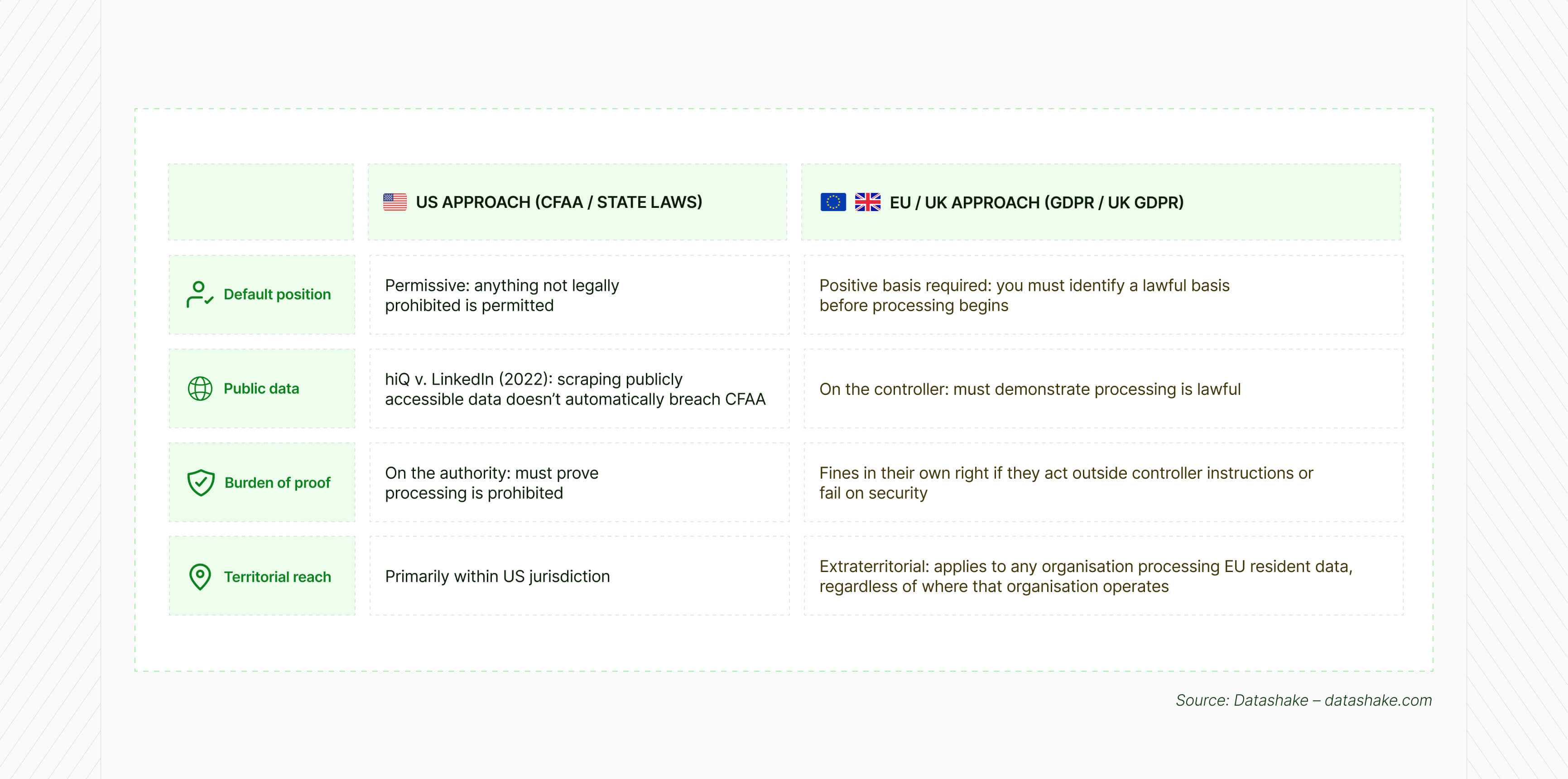
A US vendor legally collecting data under US law may still be processing that data in ways that don’t meet GDPR requirements – particularly around documented lawful basis, retention limits, and data subject rights infrastructure.
On cross-border transfers: Moving EU personal data to systems outside the EEA requires a formal transfer mechanism. The EU–US Data Privacy Framework adequacy decision was upheld in September 2025, but given the history of legal challenges to these frameworks, maintaining Standard Contractual Clauses (SCCs) alongside it is sensible practice. Any provider handling EU data in US infrastructure should name the mechanism they’re using.
Why compliance-first teams move faster
The framing of GDPR as something that slows product teams down is largely a function of encountering it late: when requirements arrive as surprises during procurement, or when an erasure request surfaces and the infrastructure to handle it doesn’t exist yet. Teams that build correctly from the start don’t face those problems.
There’s also a commercial angle worth being direct about. Enterprise deals in regulated industries (pharma, financial services, healthcare) often come down to compliance posture. A DPA that can’t be produced on request, or an erasure process that doesn’t exist, can kill a deal that was otherwise done.

The European Commission’s Digital Omnibus proposal from November 2025 also signals the direction of travel: it proposes to explicitly codify that AI model training using personal data can qualify as legitimate interest under strict guardrails. The regulatory environment is moving toward workable frameworks for data products, but those frameworks still require documented compliance work, not assumptions.
TL;DR: What to take away from this
1. GDPR applies to public social data — but that doesn’t make it off-limits. It means the collection needs a lawful basis and the data needs to be handled responsibly. Both are achievable with the right foundation.
2. Legitimate Interest is the right and appropriate legal basis for social intelligence use cases — when supported by a documented three-part LIA. Your provider’s LIA covers their collection. You need your own for your product use case.
3. A compliance-first provider handles the hard parts: lawful basis documentation, platform access controls, DPA, sub-processor governance, retention, and deletion support. Your team documents your use case, signs the DPA, and handles direct data subject requests.
4. Get a DPA with every data vendor. It’s legally required under Article 28. It’s also the most reliable early signal of a provider’s actual compliance posture — more so than anything on their website.
5. Design erasure into your architecture from the start. It’s far harder to add later than it looks. Erasure requests are rare, but when they arrive you have 30 days — and regulators are actively checking.
6. The enforcement cases are all about the same failures: collection beyond stated purposes, no retention limits, use cases individuals couldn’t anticipate, transfers without safeguards. None of this is inherent to social data — it’s about how it’s built.
7. Compliance built in is a commercial advantage. It shortens enterprise procurement cycles, opens regulated-industry deals, and means your team builds on social data with confidence rather than caution.
Ready to build on social data with confidence?
A lot of teams come to Datashake after spending too long treating social data as a legal grey area. Datashake is built for social intelligence and review aggregation use cases – with the documentation, DPA, and infrastructure to back it up.
💡 If you're evaluating providers or looking to replace something you've built in-house, we're happy to walk you through how we approach this. Book a call with our team
Related: Should You Build vs Buy Your Social Media Data Pipeline?



More insights you might like


%20Get%20in%202026%20Thumbnail.jpg)