TikTok vs Reddit: Where Are Communities Actually Talking?

If you’re building a social intelligence foundation, running competitive monitoring, or sourcing data for AI models, you've probably had this talk: "Should we prioritise TikTok or Reddit coverage?"
This is a question about the fundamental architecture of two very different types of online communities, what kind of data each produces, and whether that data is actually accessible to you.
The short answer is that Reddit and TikTok are not interchangeable — and both are growing fast at a moment when the platform that used to own this space is losing ground.
- Reddit: 471.6 million weekly active users, $2.2 billion in revenue in 2025, up 69% year-on-year
- TikTok: approximately 2 billion monthly active users globally as of 2026, growing at 17% annually – faster than LinkedIn, Instagram, or any other major platform
- X usage among US teens has dropped from 33% in 2014 to 16% today.
The platform that used to be the default surface for real-time social data is contracting. Reddit and TikTok are where the conversations moved – but they produce fundamentally different data, with different structures, different access constraints, and different analytical requirements.
This post breaks it down across six dimensions: platform architecture, data structure, coverage and freshness, use case fit by vertical, data access realities, and a practical decision framework for teams building on social data infrastructure.
Let’s dive right in ⬇️
QUICK ANSWER
Reddit gives you depth. TikTok gives you scale. They produce fundamentally different data (different structure, different access constraints, different analytical requirements) and most social data use cases need both.
Reddit: Community-oriented by design. Power users and enthusiasts self-organise into 138,000 active subreddits to talk seriously about their passions and interests. The result: long-form, threaded, text-native discussion that persists for years. API expensive but accessible.
TikTok: Interest-graph driven. No fixed communities, 2 billion users served personalised content by an algorithm. Short-form, emoji-heavy, real-time, demographically broader. API restricted by design.
1. Platform architecture: why the underlying model changes everything
The most important thing to understand about TikTok and Reddit is not their size or their demographics. It's the logic of how content gets organised and surfaced, because that determines what kinds of conversations happen and how easy they are to extract signal from.
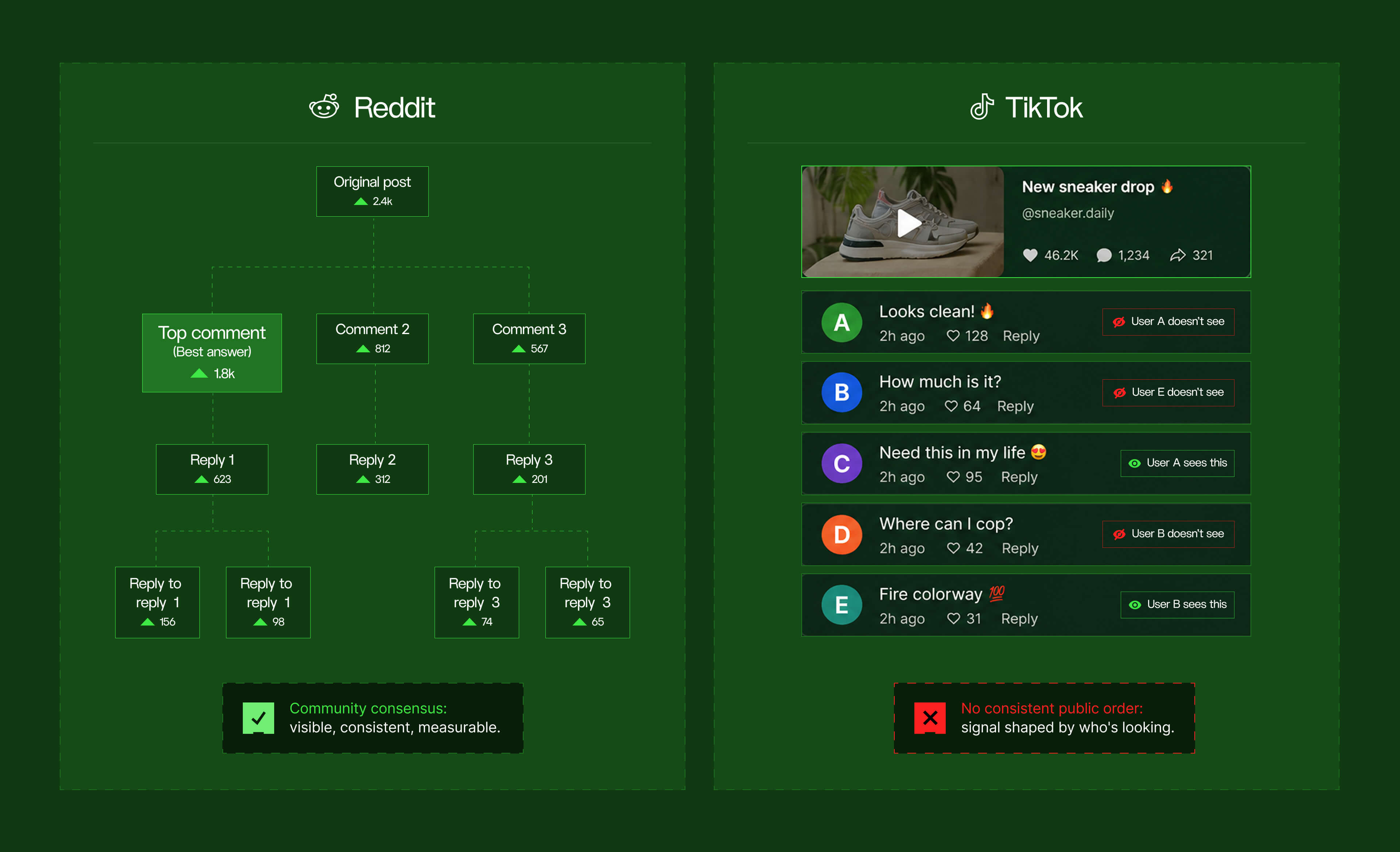
TikTok’s interest graph
TikTok is built around what's known as an interest graph.
The platform doesn't require users to join communities or follow accounts. It watches behaviour (watch time, replays, skips, shares) and infers preferences in real time.
This creates a highly personalised, individual feed. Two users in the same city with similar demographics can have completely different experiences of the platform depending on what they've engaged with.
There are no fixed community containers. Content clusters around hashtags like #FinTok or #SkincareTok, but these are loose interest signals rather than structured communities with rules and persistent identity. Content is primarily video. The text data that exists lives mostly in comment sections, which are short, emoji-heavy, and often reactive rather than substantive.
TikTok's comment sections are personalised too
TikTok's comment sections are themselves algorithmically ranked. A 2026 paper from the AAAI found that TikTok uses personalised ranking for comment visibility, meaning different users see different comments under the same video.
Unlike a Reddit thread where the top comment reflects community consensus via upvotes, a TikTok comment section has no consistent public order. This makes it harder to extract reliable community sentiment from comment data, because the signal is partially determined by who's looking.
💡 The personalisation problem isn't unique to TikTok. Structural data incompleteness affects most platforms, and most teams don't know where their gaps are until an insight comes back wrong.
Reddit’s community graph
Reddit is organised around 2.8 million topic-specific communities called subreddits, 138,000 of which are actively maintained. Each subreddit has its own rules, moderators, community norms, and culture. Users navigate to them deliberately. If you want to participate in r/datascience or r/SkincareAddiction or r/AskEngineers, you go there intentionally.
Content is sorted using a public ranking formula that balances upvote score and recency. Critically, this ranking is the same for everyone, it's not personalised per user. The most upvoted content in a subreddit reflects community consensus in a way that's visible, consistent, and measurable.
This creates threaded text discussion at scale. Reddit has accumulated over 24 billion posts, comments and conversations. An Oxford Digital Scholarship in the Humanities paper (2025) describes Reddit as a "pluricentric entity" whose subreddit communities produce distinctly different communicative patterns – making it a rich and varied environment for text analysis.
TikTok tells you what's capturing individual attention, right now. Reddit tells you what communities think, and why, with their reasoning visible and searchable.
2. Data structure: what you're working with
Reddit produces long-form, threaded text organised into nested comment trees, with each post containing a title, body text, upvote score, subreddit label, and branching replies that preserve the full context of a conversation. TikTok's primary data unit is a short video, with text signal limited to brief, emoji-heavy comments under each video: flat in structure, short in length, and algorithmically ranked differently for each user. For teams building social data pipelines, this means Reddit data is text-native, hierarchically structured, and well-suited to NLP analysis, while TikTok data requires significantly more pre-processing to yield reliable signal.
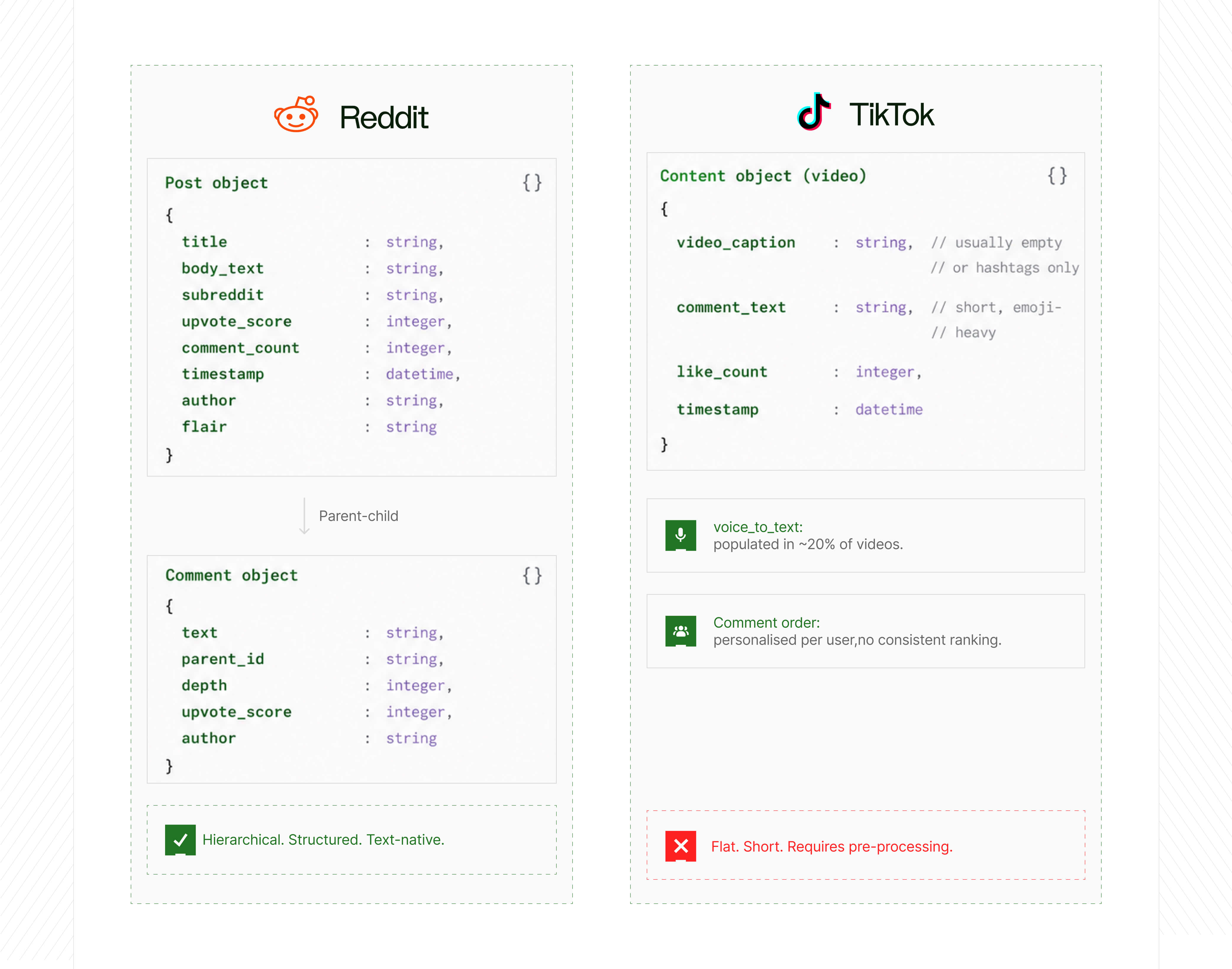
Reddit data structure
Reddit data is text-native and hierarchically structured. Each post contains:
- Post object: title (plain text), body text (selftext), subreddit, author, timestamp, upvote score, number of comments, post flair/category label, link URL if applicable
- Comment tree: comments are structured as nested trees, with each comment containing its own text, author, upvote score, parent ID, and depth level. This threading is preserved in the API response
- Subreddit metadata: community name, subscriber count, category, community rules – all accessible and useful for segmentation
- Historical depth: Reddit's public archive goes back to 2005. The Pushshift project indexed billions of posts before API restrictions; Reddit's own API allows historical access within pricing tiers
- Engagement metrics: upvote/downvote ratio, upvote score, comment count, award count, and share count at post level; upvote score and reply count at comment level. Crucially, upvote ratio is public and consistent – the same signal for every user, making it a reliable proxy for community consensus
Why Reddit is a better NLP surface than it gets credit for
Reddit text is unusually rich for NLP and sentiment analysis. Posts are typically written in complete sentences. Users explain their reasoning, make comparisons, use product names explicitly, and engage in multi-turn debate.
But the real signal advantage is in the comments. Because Reddit self-selects for passion-driven, knowledgeable users (people who sought out a specific community because they genuinely care about the topic) the comments section is qualitatively different from what you find elsewhere.
➡️ You're not wading through "love this!" and single-emoji reactions. You're reading detailed opinions, technical corrections, personal experience accounts, and structured disagreements from people who actually know what they're talking about. That's a very different NLP surface from a TikTok comment thread or an Instagram caption.
A 2024 PACMHCI study on Reddit conversation structure found that scientific, political and current events subreddits generate particularly deep and wide discussion trees – meaning the analytical surface area scales with topic sensitivity.
Upvotes are a quality filter
The upvote system functions as a community-level quality signal. Highly upvoted content has been validated by the community. For brand research, competitive intelligence or product feedback, this means you can distinguish what the community endorses from what it tolerates.
TikTok data structure
TikTok's primary content unit is a video. The text data available to external systems consists of:
- Video caption: typically short, often just hashtags, rarely substantive text
- Comments: short reactions, often single words, emoji strings, or brief phrases. Technically flat (not threaded in the same way as Reddit). Average comment length is far shorter than Reddit
- Hashtags: the primary signal for content categorisation, though hashtag use is loose and inconsistent across users
- Video transcription: TikTok's Research API includes a voice_to_text field, but a study on the Research API found only one in five videos had this field populated
- Historical depth: extremely limited. TikTok's content is designed to be ephemeral. Historical data access is constrained by both API design and platform policy
- Engagement metrics: like count, comment count, share count, and play count at video level; like count only at comment level. Unlike Reddit's upvote ratio, none of these signals reflect community consensus – a video with 10 million views and 50,000 likes tells you it was served widely by the algorithm, not necessarily that the audience endorsed it. Share count is arguably the highest-quality signal, but it's not always accessible via the API
TikTok comments are hard to analyse at scale
TikTok comments present challenges for sentiment analysis. A 2025 academic study noted "extreme brevity, informal and evolving slang, heavy emoji usage, and multilingual content" as the primary difficulties. Unlike Reddit text, which tends to be long enough for robust NLP pipelines, TikTok comments often need specialised models and significant pre-processing before they yield reliable sentiment signals.
A challenge for normalisation
If you're building a platform that ingests data from both Reddit and TikTok into a unified schema, you're working across fundamentally different data models.
➡️ Reddit gives you threaded conversation trees. TikTok gives you flat comment lists under video objects. Reddit text is paragraphs; TikTok text is fragments. Reddit has upvote consensus signals; TikTok has like counts but with algorithmically filtered visibility.
Getting both into a consistent, clean, deduplicated schema – one that lets you run comparative analysis across platforms – is the real challenge. ⚠️
3. Coverage, freshness, and the problem with representativeness

Two questions that rarely come up when teams evaluate social data sources, but should:
How fresh is the data?
Reddit posts are crawlable as soon as they're public. Comments accumulate over hours, days, and sometimes years on popular threads. For most monitoring use cases, latency of a few hours is acceptable.
⚠️ Crisis detection is the exception: as we've written about in the context of our headless social listening piece, if a thread starts gaining traction at 9am and your pipeline has a 4-hour crawl delay, you're seeing it at 1pm after the first articles have already been written.
TikTok data is fresher in theory than in practice
TikTok presents a more complex picture when it comes to data freshness. The platform sends webhook notifications for new comments, but Sprinklr's documentation notes a 2–3 hour delay for comment data following TikTok's API update in July 2025. The Research API has documented accuracy gaps: view and engagement counts can take up to 10 days to populate accurately after publication, according to TikTok's own documentation.
How representative is each platform?
- Reddit skews heavily toward English-speaking, Western internet users
- Over 50% of traffic comes from the US, with Canada, UK and Australia as the next largest contributors
- The gender split is roughly 60% male / 40% female
- The platform significantly over-indexes on higher income brackets and educated users
- If your use case requires monitoring consumer sentiment for a global consumer brand with significant markets in Southeast Asia, Latin America, or non-English-speaking Europe, Reddit's coverage will have systematic blind spots.
TikTok is demographically much broader.
- With approximately 2 billion monthly active users across 150+ countries and genuinely balanced gender distribution, it offers coverage that Reddit can't match for global consumer categories
- For understanding how a beauty product or a fast food brand is perceived by 18–24 year olds across Indonesia, Brazil and the US simultaneously, TikTok has signal that Reddit simply doesn't.
The 50% Rule applies here: if you're only monitoring one of these platforms, you're making coverage decisions that will systematically bias your analysis toward certain demographics, geographies, and content types.
Why neither platform is enough on its own
The coverage gap only gets steeper with the data depth gap. Reddit gives you rich signal from a narrow demographic. TikTok gives you thin signal from a broad demographic. Neither alone gives you a representative picture of how a topic is discussed across the full population that matters to your users.
💡 If you're not sure whether your current coverage is representative of the population that matters to your users, this framework walks through exactly how to evaluate it.
4. Reddit or TikTok? It depends on the use case
Different segments of the social intelligence market extract different value from each platform. ⬇️
💡 For a deeper look at how each of these use cases plays out in practice – including the specific source types and data characteristics each one requires – this post covers the most impactful social data use cases in 2026.

Social intelligence platforms
Reddit is an essential source for social intelligence products because it's where the highest-intent, most reasoned consumer discourse lives. Sprinklr describes Reddit's value specifically in terms of "depth over speed" compared to TikTok and X. Users come to Reddit to evaluate, compare, and decide, not just to react.
Reddit is where trends are born
Brandwatch, Sprinklr and others have documented the pattern of Reddit conversations surfacing before they reach mainstream platforms. The CeraVe/Michael Cera campaign is a good example: a Reddit joke circulated for years before becoming the foundation for a Super Bowl campaign generating 15 billion+ earned impressions. Your social intelligence product's value to clients includes catching these signals early.
TikTok adds real-time cultural velocity that Reddit doesn't offer. But is your coverage of both deep enough to catch a signal wherever it originates?
Online reputation management platforms
Reddit is arguably the most important unstructured text review surface that exists for many product categories.
When someone searches "is [product] worth it," the top results are frequently Reddit threads. Reddit appears in 97.5% of Google product review queries. Your users' customers are going to Reddit to form opinions about their products before buying.
TikTok reputation monitoring: consumer yes, B2B no
TikTok matters for reputation management in consumer categories with strong Gen Z or visual-first audiences: beauty, fashion, food, fitness. The comment sentiment under brand-relevant videos is a leading indicator of how a product or campaign is landing with that demographic. For B2B or niche professional categories, TikTok's relevance drops considerably.
Customer experience platforms
The value Reddit provides to CX platforms is the depth and specificity of user feedback. When customers describe a product failure on Reddit, they tend to explain what they expected, what happened, what they tried, and how it compared to alternatives. That's a qualitatively different signal from a 2-word TikTok comment or even a 3-star review with no body text.
Unfiltered product feedback at scale
For CX teams and product managers trying to understand what customers genuinely think (not just what incentivized surveys capture) Reddit threads are a primary research surface. The data is messy but rich. TikTok comments provide directional sentiment at scale but lack the depth needed for product decision-making.
Marketing automation platforms
This is where TikTok's interest graph architecture creates a lot of value. TikTok's algorithm is exceptionally good at identifying emerging consumer interest before it reaches other platforms. A 2025 TikTok Creator Trends report noted that videos tagged with niche community hashtags see 43% higher engagement than general content. TikTok's velocity is a real asset for marketing automation platforms that help clients identify what's resonating with target audiences in near real-time.
Reddit is a keyword research tool hiding in plain sight
Reddit is key for marketing automation in a different way: keyword discovery. The specific language communities use to describe problems, products, and preferences on Reddit is high-quality input for ad copy, content strategy, and audience targeting. Because Reddit users are searching for answers and explaining themselves, the text is much closer to actual search intent language than TikTok comments.
💡 For pharma and life sciences teams specifically, we've written a full breakdown of how adverse event monitoring works on social data – including the source types and pipeline requirements the use case demands.
5. Platform coverage means nothing if you can't access the data
Reddit's official API requires enterprise pricing starting in the thousands of dollars monthly, but returns clean, text-native, structured data with extensive historical depth. TikTok's Research API is restricted to academic researchers, capped at 1,000 requests per day, and has documented gaps of around 12% of content that cannot be retrieved even with approved access. For commercial social listening, TikTok access only improved meaningfully following an API update in July 2025, and major listening platforms still describe it as limited. In practice, Reddit data is expensive but accessible and structurally consistent; TikTok data is restricted by design and carries additional regulatory uncertainty tied to ongoing US ownership requirements.

Reddit shifted to an enterprise pricing model in 2023. Official API access starts in the thousands of dollars monthly with no published standard rate card, as pricing is negotiated per use case. This effectively priced out independent developers and academic researchers on standard budgets.
What you get in exchange: clean, text-native, structured data. Post titles, body text, comment trees, timestamps, upvote scores, subreddit labels. The threaded structure is preserved in API responses, which means you can analyse conversation depth, reply patterns, and consensus emergence rather than just individual posts.
💡 If this section is making you wonder whether it's worth building these pipelines independently at all, we've worked through the full cost analysis – including where the hidden costs of building tend to surface.
If the world's largest AI companies are paying for it, there's a reason
Reddit has also signed major data licensing deals with Google (~$60M/year) and OpenAI (~$70M/year) for LLM training access. Yes, the corpus is valuable enough that the world's largest AI companies are paying meaningfully for it.
Third-party data providers offer Reddit data access at more accessible price points than the official API, with the engineering work of normalisation and deduplication handled upstream.
TikTok
TikTok's Research API is restricted to academic researchers at non-profit universities in the US and Europe. Even that access has documented gaps: a June 2025 investigation by AI Forensics found that one in eight videos from user data donations cannot be retrieved through the API, prominent accounts' content is inaccessible, and approximately 1% of creators are excluded without explanation and without disclosure.
TikTok's research tools don't work the way the platform implies
A separate investigation by Democracy Reporting International, which was granted TikTok's Virtual Compute Environment access for civil society research ahead of Germany's 2025 elections, described "two dysfunctional and restrictive tools that fall short of fulfilling the spirit of the DSA". The standard Research API rate limit is 1,000 requests per day, capped at 100 videos per request.
Better than it was. Still not good enough
TikTok access improved marginally for commercial social listening. Sprinklr gained the ability to access comment and video post mentions following a TikTok API update in July 2025, with a 2–3 hour delay. But direct TikTok social listening is deeply limited due to API restrictions, a position that major listening platforms have had to work around, not solve.
The geopolitical dimension
TikTok carries a platform risk that Reddit does not.
The most significant market loss came first: India banned TikTok in June 2020, cutting off what was then the app's second-largest market of 200 million users overnight. The ban remains in place. That's a permanent, unrecoverable gap in any TikTok-dependent data pipeline covering the Indian market.
The US Supreme Court upheld legislation enabling a TikTok ban in January 2025. The platform went dark for 14 hours before executive action restored it. A joint venture structure with an American-majority consortium closed in January 2026, but the underlying regulatory uncertainty has not been resolved.
The platform remains subject to potential shutdown on 75 days' notice. For teams building data pipelines that depend on TikTok access as a core input, this is an infrastructure risk with no equivalent on the Reddit side.
💡 A question that always surfaces here: if official API access is expensive or restricted, is collecting data through other means actually legal? The short answer is more nuanced than most people expect.
6. Reddit's growing role in AI and search infrastructure
One shift that has materially changed the Reddit picture for social data teams is its integration into search and AI retrieval systems. ⬇️
Why AI systems keep citing Reddit
Reddit threads now appear in Google AI Overviews. Reddit signed a $60M/year data licensing deal with Google and a comparable deal with OpenAI. They're paying for the corpus because it contains what AI systems need: structured, voted, human-verified, contextually rich text.
💡 If your use case is AI training data specifically, we've written a guide on why social data is becoming the most valuable training asset in the market – and what makes Reddit's corpus structurally different from synthetic alternatives.
50 times fewer citations is a data infrastructure problem
According to Tinuiti's AI Citations Trends Report Q1 2026, social media content accounts for a growing share of AI citations, with Reddit dominating across tracked product categories. Research by SE Ranking found that brands with significant Reddit community activity have roughly four times higher chances of being cited by AI systems than those without it. TikTok, by contrast, receives 50 times fewer AI citations than Reddit across major AI platforms - reflecting both the text-native advantage and the access constraints.
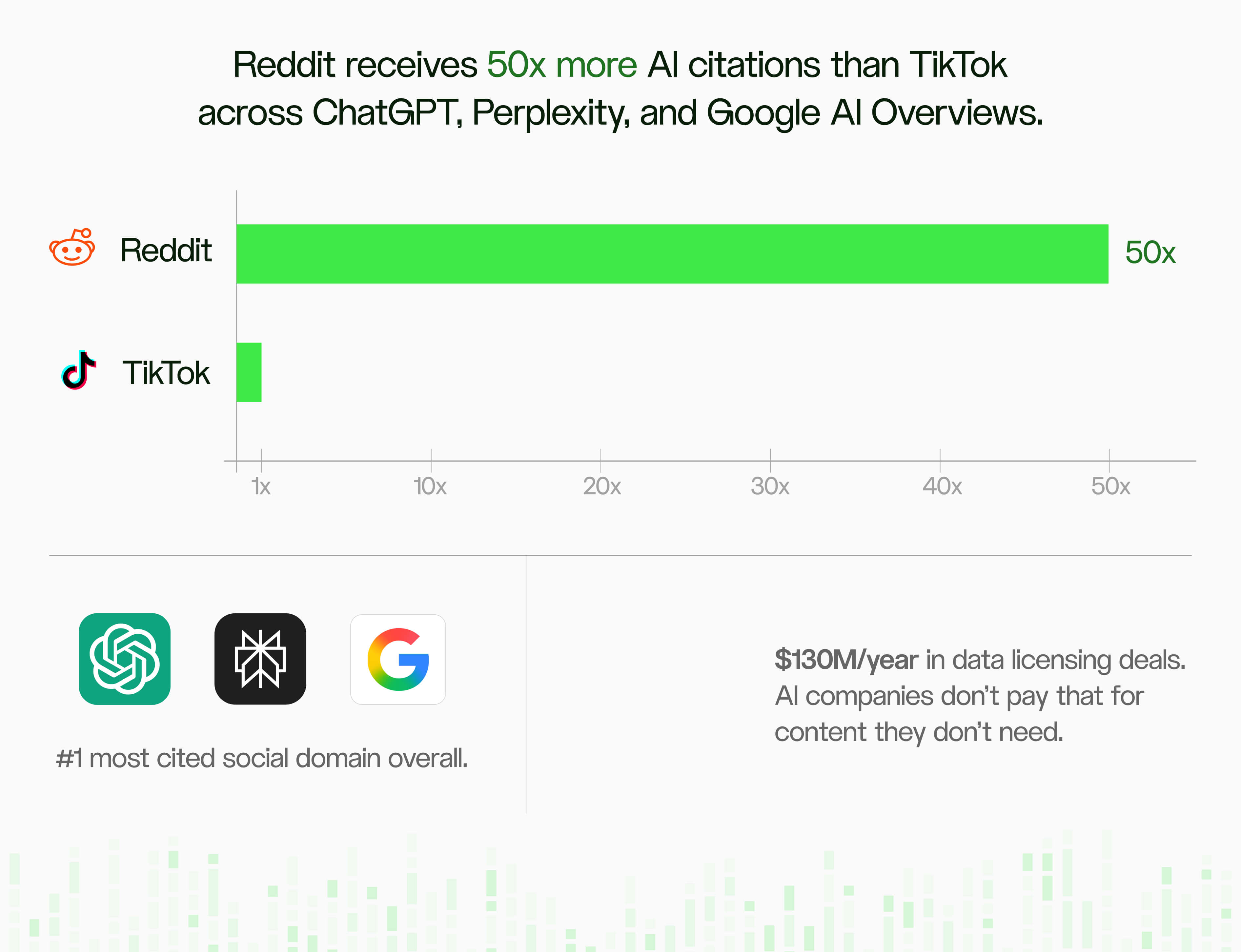
Users are leaving curated feeds for unfiltered opinion. The data follows
In practical terms for social data teams: Reddit is increasingly the surface where a brand's perception is being formed, indexed, and cited by AI systems that are becoming the first stop for consumer research. In the UK, Reddit overtook TikTok to become the fourth most-visited social platform in early 2026, with 88% reach growth over two years. The growth is being driven by what Ofcom and others are calling a "flight to authenticity": users specifically seeking out unfiltered human opinion, away from algorithm-optimised influencer content.
TikTok is where culture moves fastest. Reddit is where it gets discussed, archived, and cited by the systems increasingly shaping what people believe about products and brands. Both functions have value. They're just different functions.
7. Decision framework: which platform matters for your use case?
Here's a practical guide for social data teams evaluating coverage priorities.
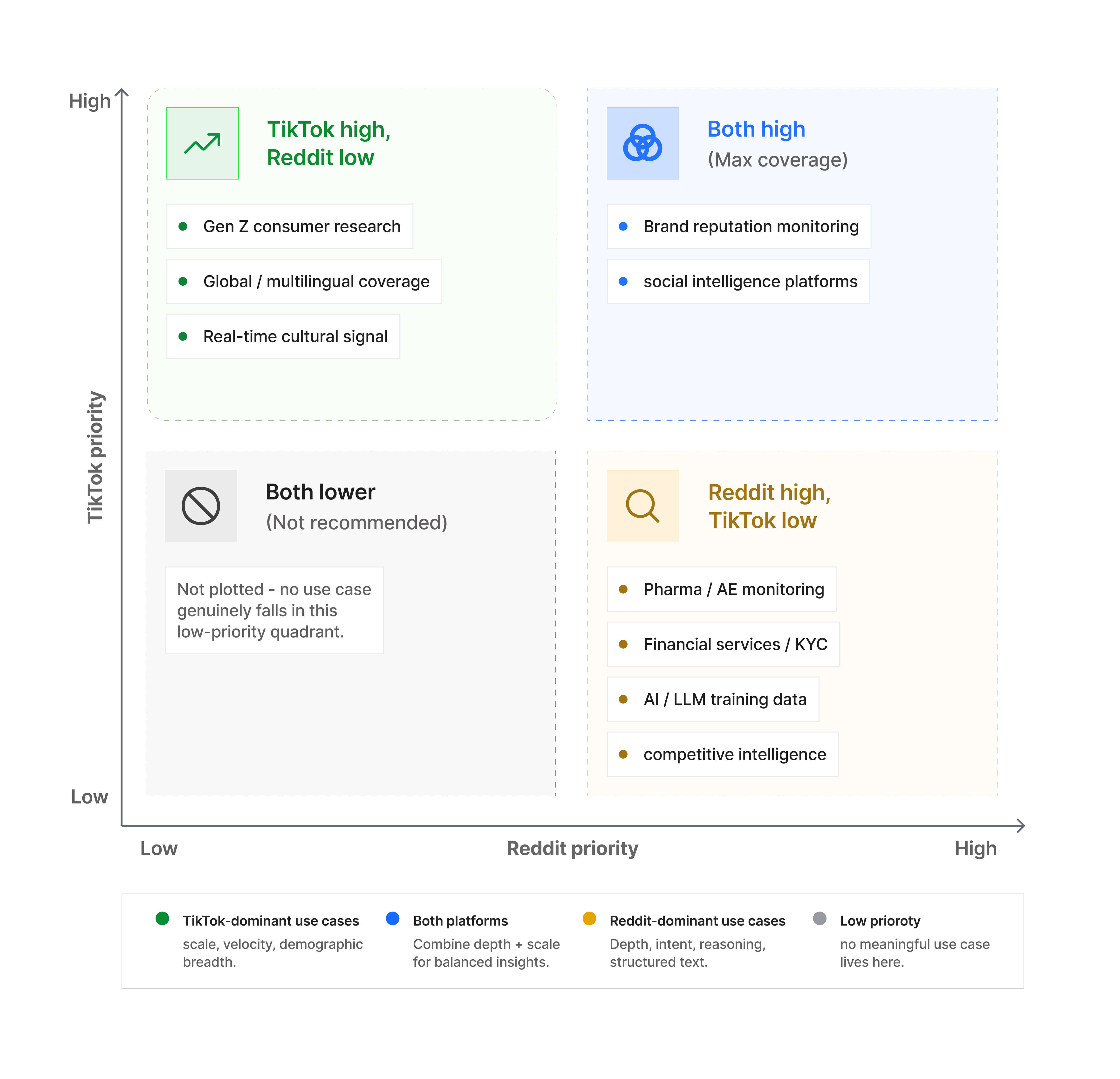
The most important insight: very few use cases are well-served by a single platform. Most require both, but for different functions at different points in the analytical workflow.
8. Full comparison at a glance
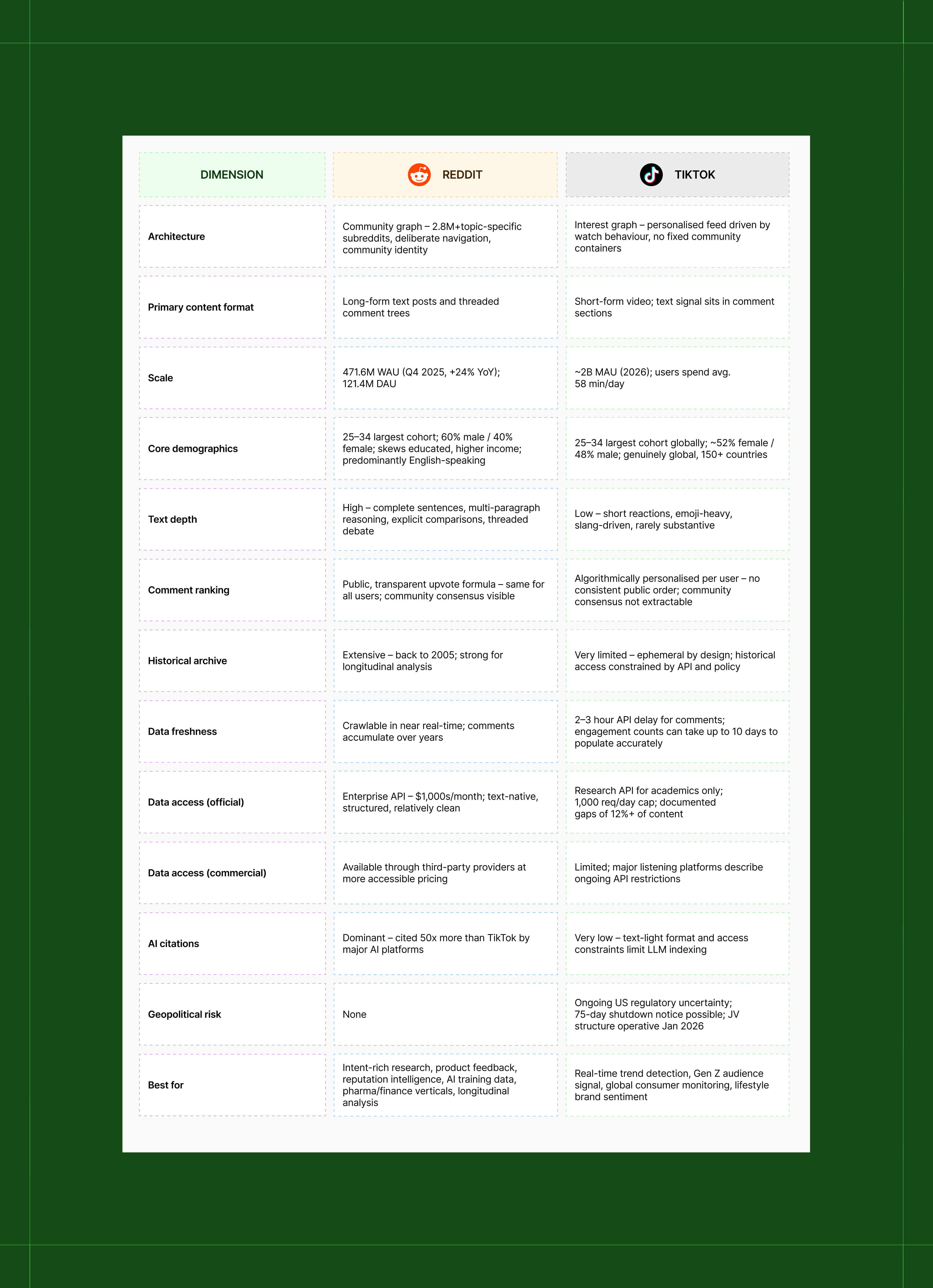
What this means for what you build
The question we like to ask: What does your data infrastructure need to produce, and which sources are required to produce it without systematic coverage blind spots?
Reddit gives you depth – structured, text-rich, archived community reasoning that serves product intelligence, competitive research, and LLM-visible brand presence. TikTok gives you breadth and velocity, fast-moving cultural signal from a broader demographic at global scale.
For social intelligence, reputation management, customer experience, and marketing automation platforms, the answer to "which one?" is almost always "both, for different reasons, with different analytical treatment applied to each."
The practical constraint is access. Reddit's enterprise pricing and TikTok's restrictive API mean that building reliable, high-fidelity coverage of both platforms independently is expensive, complex, and brittle to platform policy changes. This is precisely why the architecture of your data source matters as much as which platforms you claim to cover – having both in your pipeline is table stakes, but having both at production-grade quality, with consistent schema and managed latency, is where the actual differentiation is.
The platforms are different. They were always going to be different. The question is whether your infrastructure is built to handle both of those differences without losing signal quality in the translation.
💡 If you're building on social data and want all platforms in one clean pipeline
Stop stitching together two broken pipelines. Get 150+ other source types through one integration, one schema, ready to use.
If what you've read here maps to a problem you're actually trying to solve, the fastest next step is a short call with our team to talk through your specific use case and data requirements.
Or if you'd rather start with the data: explore Datashake →
Frequently asked questions
What is the difference between Reddit and TikTok data for social listening?
Reddit produces long-form, threaded text organised into topic-specific communities, with upvote-validated consensus visible and persistent across years. TikTok's signal sits primarily in short comment sections under videos – brief, emoji-heavy, and algorithmically ranked differently per user. Reddit is suited to deep qualitative analysis and intent research; TikTok is better for high-volume directional sentiment and real-time trend detection.
Which platform is better for brand reputation monitoring?
Reddit is more valuable for most categories because threads rank in Google, are cited in AI-generated answers, and contain the structured reasoning that shapes brand perception before purchase decisions. TikTok is more relevant for consumer brands with Gen Z or visual-first audiences (beauty, fashion, fitness, food) where comment sentiment under brand videos is a meaningful leading indicator. For B2B or niche professional categories, TikTok's relevance drops considerably.
Can you access TikTok data for commercial social listening?
Access is limited. TikTok's Research API is restricted to academic researchers and has documented gaps covering approximately 12% of content that cannot be retrieved even with approved access. Commercial listening platforms gained limited access following a TikTok API update in July 2025, with a 2–3 hour delay, but major platforms still describe it as constrained. Reddit's enterprise API is expensive but structurally complete and text-native. Third-party data providers offer more accessible access to both platforms.
Which platform do AI systems cite more frequently?
Reddit dominates AI citations by a wide margin. Research across ChatGPT, Perplexity, and Google AI Overviews shows TikTok receives approximately 50 times fewer AI citations than Reddit. Reddit is the most-cited social domain overall across major AI platforms, driven by its text-native format, structured content, and the data licensing deals signed with Google ($60M/year) and OpenAI (~$70M/year). TikTok's short-form video format and limited API access contribute to its very low AI citation rate.
What are the main challenges with TikTok comment data for sentiment analysis?
TikTok comments present significant NLP challenges: extreme brevity, informal and rapidly-evolving slang, heavy emoji usage, and multilingual content – all documented in published academic sentiment research. Unlike Reddit text, which is typically long enough for standard NLP pipelines, TikTok comments require specialised models and substantial pre-processing before yielding reliable sentiment signals. The additional complication is that TikTok comment sections are algorithmically personalised per user, meaning there is no consistent public ranking to extract community consensus from.
How does Reddit's upvote system affect data quality for social intelligence?
Reddit's upvote system functions as a community-level quality filter that has no equivalent on TikTok. Highly upvoted content has been validated by the community as useful, accurate, or representative. For brand research, competitive intelligence, and product feedback, this means you can distinguish what a community endorses from what it merely tolerates – a signal that is machine-readable, consistent across users, and stable over time. This consensus visibility is one of Reddit's most significant data quality advantages over other platforms.
Should a social intelligence or reputation management platform cover both Reddit and TikTok?
Yes, but for different reasons and with different analytical approaches. Reddit provides intent-rich, text-native, archived community discourse suited to product research, competitive intelligence, and LLM-visible brand presence. TikTok provides real-time cultural velocity and broad demographic coverage, particularly for consumer categories with Gen Z audiences. Covering only one introduces systematic blind spots.



More insights you might like


