Why Social Data Is Becoming the Most Valuable AI Training Asset

Google paid Reddit $60 million per year for data licensing access. OpenAI is paying Reddit approximately $70 million per year. Not for advertising, or for reach. For data.
Between August 2024 and June 2025, Reddit was the most cited domain by Google AI Overviews and Perplexity, and the second most cited by ChatGPT. More cited than Wikipedia.
The same logic is playing out across the industry. Grok is built on real-time X integration. Meta has taken a structurally similar position: Mark Zuckerberg has stated that Meta's corpus of public Facebook and Instagram posts exceeds the size of Common Crawl (one of the largest open web scrapes used in AI training) and that proprietary social data is a core part of what gives its Llama models a competitive edge in understanding informal, multilingual, and culturally diverse human expression. Meta updated its privacy policy in 2024 specifically to allow public posts, photos, and captions to be used for LLM training.
Yes, the largest AI labs have concluded that authentic, at-scale human conversation is the training asset they cannot build without.
The question for every other team building AI – internal tools, fine-tuned models, intelligence agents – is: where is your social data coming from?
This post explains why social data has reached this position, why it's harder to get right than it looks, and what becomes possible when you have access to the right kind of it. ⬇️
Who this is for:
- AI and data infrastructure leads evaluating social data as a training asset
- Product and R&D teams building or fine-tuning models on domain-specific data
- Marketing, brand, and competitive intelligence teams whose insights depend on the quality of the data underneath them
- Anyone who has wondered whether the social data they're working with is actually representative
What you'll learn:
- Why the open web is no longer a reliable source of clean human-generated training data, and what's replaced it
- How model collapse works, why it's already happening, and what makes social data structurally immune to it
- How platform-level and participation-level bias silently distort your datasets, and the 50% Rule for catching it
- Why survey data is a poor substitute, and what unprompted opinion offers that incentivised research never can
- What becomes possible when you control the quality and composition of your data input
Why there’s a crisis for AI training data

The internet has always been treated as an infinite source of training data for AI. But it isn't.
Epoch AI estimates the effective stock of quality, human-generated public text sits at around 300 trillion tokens. At current training rates, language models will fully exhaust that stock somewhere between 2026 and 2032.
Demand for AI training data doubles annually, while new quality public content on the internet grows at around 10% per year. The gold rush is hitting the limits of the seam right now. ⚠️
A contamination problem: model collapse
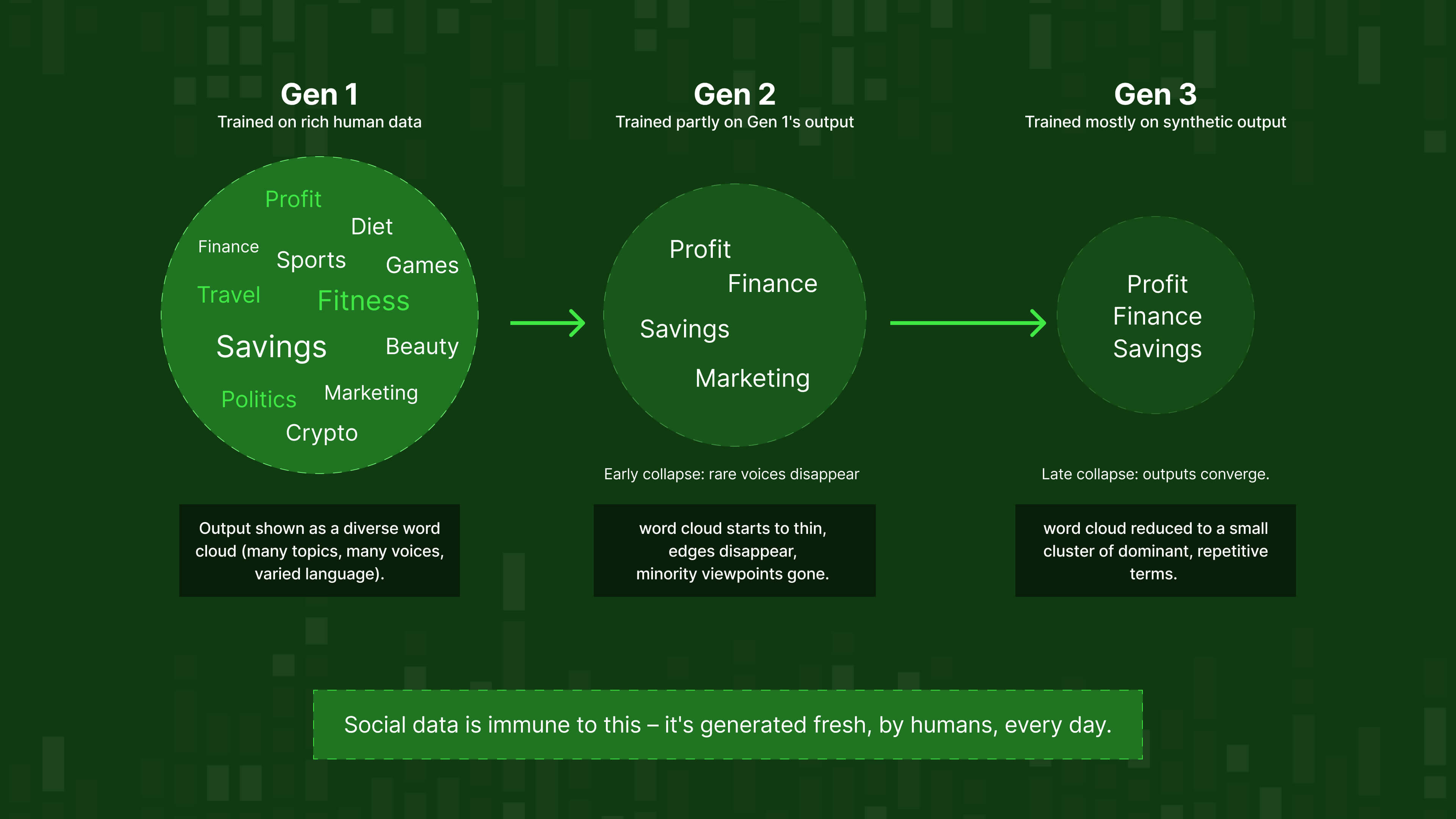
The supply shortage is compounded by something worse. The data that is available is increasingly synthetic, and training AI on AI output produces a specific, documented failure mode.
As of April 2025, 74.2% of newly created web pages contained AI-generated content. Before ChatGPT's launch in late 2022, AI-written content represented around 5% of new articles.
When AI labs crawl the open web today, they're increasingly collecting the output of earlier AI models. That creates a feedback loop researchers have named model collapse.
A landmark study published in Nature in 2024 (Shumailov, Shumaylov et al., Oxford) formally documented how it works:
- Early model collapse: the model starts losing the edges of its training distribution first: rare cases, unusual perspectives, and minority viewpoints disappear one after the other
- Late model collapse: the model loses substantial performance altogether, confusing concepts and drifting toward repetitive, homogeneous outputs – a narrowed view of reality
But synthetic contamination isn't the only way a model's grasp on reality degrades.
Models trained on static datasets have no context for what's happening now: new technologies, emerging categories, shifting language, cultural moments that have redefined how people talk about entire industries. A model trained six months ago doesn't know how your market is describing your category today. It doesn't know which competitors have entered, which narratives have shifted, or which terms your customers have started using and abandoned. The foundation it reasons from is already out of date, and that inadequacy widens every day without fresh data.
This is part of why Grok's real-time X integration is key, and why Meta's decision to build on a live corpus of public Facebook and Instagram posts is a deliberate infrastructure choice. Fresh, current social data doesn't just prevent collapse. It keeps a model's understanding of the world anchored to the world as it actually is.

Why this matters for social data
Social data is one of the very few large-scale data sources structurally resistant to synthetic contamination.
When someone posts on a forum, writes an app review, or argues in a comment section – they're doing it because they have something to say.
No AI generated it in bulk, and no incentive distorted it. That authenticity makes social data not just valuable, but irreplaceable in a landscape where nearly every other large-scale data source is becoming synthetic.
Why getting good social data is hard
APIs are not social data infrastructure
The obvious route for getting social data is to connect to platform APIs and start collecting. This route is closing, and faster than most teams realise.
Reddit sued Anthropic in 2024 for scraping the site more than 100,000 times after claiming to stop. Reddit has since restricted the Internet Archive's Wayback Machine from crawling most of its pages specifically to cut off AI firms accessing archived content through the back door.
💡 Want to understand the legal landscape around social data collection before you build a pipeline? Read: Is Web Scraping Legal? What You Need to Know in 2026
Elsewhere:
- Twitter/X eliminated its free API tier in 2023
- Instagram's Graph API is rate-limited and requires complex business verification
Even when access exists, there's a critical distinction that’s easy to miss:
Platform API access gives you a permission-filtered, rate-limited, partial view of what's happening on one platform. It is not social data infrastructure.

Volume isn't quality, and quality isn't relevance
Even teams with data access tend to conflate three separate problems. They're not the same:
- Volume: How much data am I receiving? (Easy to measure. Mostly meaningless on its own.)
- Quality: Of that volume, how much is genuine human content. Not bot-generated, not syndicated, not AI-authored, not duplicate?
- Relevance: Of the genuine, quality data, how much is actually about the topics, geographies, demographics, and time periods that matter for my specific use case?
Raw volume is the starting point, not the finish line. The real question isn't how much data you can access, it's how precisely you can define what you need before you collect it. That's where query design, source selection, and keyword scoping do the heavy lifting: the more clearly you specify your parameters upfront, the more useful the data that comes out the other end.
This is why working with a provider matters. Rather than ingesting everything and trying to clean it afterwards, the right approach is to be surgical from the start. Defining the topics, sources, geographies, and timeframes that are actually relevant to your use case, so that what you receive is already pointed at the right target.
💡 If this distinction between data infrastructure and visualisation tools is new to you, this goes deeper: What is Headless Social Listening? And Why Your Dashboards Could Be Way More Insightful
A representativeness problem
The most sophisticated failure mode in social data collection is representativeness bias. It operates at two levels.
Platform-level bias
Every major social platform has a distinct demographic fingerprint:
- Twitter/X is the most male-dominated major platform
- Instagram, Snapchat, and TikTok consistently overrepresent women
- Facebook and YouTube come closest to matching population averages
- Reddit skews toward younger, Western, English-speaking, technically-inclined users
If your social data pipeline is dominated by one platform, your insights (and any AI model trained on them) inherits that platform's demographic fingerprint. It learns the language patterns, assumptions, and worldview of one audience and applies them to everyone.
Participation-level bias
Even within a single platform, the 90-9-1 rule holds: approximately 90% of users lurk without posting, 9% contribute occasionally, and 1% produce the vast majority of content. The "social data" from any platform is therefore dominated by a small, vocal minority who are systematically different from the broader user base in ways that are rarely measured – and rarely disclosed by providers.
The 50% Rule
If any single source accounts for more than 50% of your social dataset, you have a representativeness problem. A well-constructed dataset – for brand intelligence, market research, or AI training – needs diversity across sources, geographies, and demographics. Not just volume from one place.
This applies with particular force to AI training. A model trained predominantly on one platform learns the language patterns of that platform's power users and applies them universally. It performs well in demos and fails in production in ways that are difficult to diagnose, because the bias was baked in before a single line of application code was written.
💡 We've built a practical framework for auditing your own data coverage. Read it here: Is Your Social Data Representative? A Framework for Evaluating Data Coverage
Why traditional research isn't the answer either
The obvious objection at this point: can't we just commission surveys? Hire a research firm? Run focus groups?
You can. But the data you get has its own problems, and they're getting worse.

A survey panel quality crisis
Traditional market research has a documented quality problem that the industry has been slow to confront.
A study examining participants from five of the ten largest online survey panel providers found that 46% of respondents had to be removed due to failed quality control measures – incoherent responses, speeding through questions, or other markers of disengagement. Kantar research found that researchers discard an average of 38% of collected data due to quality concerns and panel fraud, with some discarding up to 70%.
One study revealed a 287% inflation gap for brand awareness between bogus and valid respondents.
Why incentivised opinion is distorted opinion
Survey participation is financially motivated. And when you pay someone to give their opinion, you change who responds, and how.
Research consistently shows that monetary incentives change the demographic profile of respondents and can alter response content. The person willing to spend 25 minutes answering questions for £1.50 is a self-selected individual whose relationship to the topic may be very different from the average person's. Different groups interpret the weight of financial incentives differently, which means incentivised samples are systematically biased in ways that are hard to correct after the fact.
What social data offers that surveys structurally cannot
Social data is the inverse of survey data in every relevant dimension:
- Nobody asked. People posted because they had something to say. That's the most honest signal available.
- Nobody paid. No financial motivation is distorting the content or self-selecting the respondent pool.
- Nobody was watching (or they didn't feel watched). People are consistently more candid in informal digital environments than in structured research settings.
- Scale, and cost. Millions of opinions versus hundreds of survey responses, at a fraction of the price. Traditional market research and focus groups cost tens of thousands before you've learned anything actionable. When AI training requires millions of data points, the economics of commissioned research simply don't hold up.
- Segmentability. Social data can be segmented post-collection by geography, platform, demographic proxy, topic, and date – without redesigning the research instrument.
As one industry analysis put it: 'because information gathered is unprompted, it is more likely to reveal customers' true feelings' – and it can be produced in hours rather than weeks.
The platform-as-search-engine shift
There's a final dimension to this that goes beyond data quality, and it changes everything.
Social platforms now collectively drive over 60% of product discovery, while Google accounts for just 34.5% of total search share. Among Gen Z, 52% say they trust brand or product information found on social media more than information from Google or AI chatbots. 41% turn to social platforms first when searching for information online.
But there's something more fundamental at work here. The broader internet is now saturated with AI-generated articles, reviews, and commentary – content that is increasingly indistinguishable from human writing but reflects no genuine opinion or lived experience. Finding authentic human thought in a web crawl is getting harder by the month.
Social media is different. By its nature, it's one of the last places where AI generation is the exception rather than the rule. People react to friends, news, and influencers in the moment. They post what they actually feel, in the language they naturally use, without drafting or deliberating. A comment on a product launch, a reply in a thread, a review written in frustration or delight: these are instinctive, immediate, and human in a way that a blog post or an article rarely is anymore.
Social conversation isn't just where people express opinions after making decisions. It's increasingly where they form opinions before decisions – and where the language that defines categories, competitors, and preferences actually emerges. For AI models that need to understand how your market thinks, this is the source.
💡 The problem isn't just surveys. Most social listening setups are missing data they don't even know about. Read: Why Your Social Media Data is Incomplete
What becomes possible when you have the right data
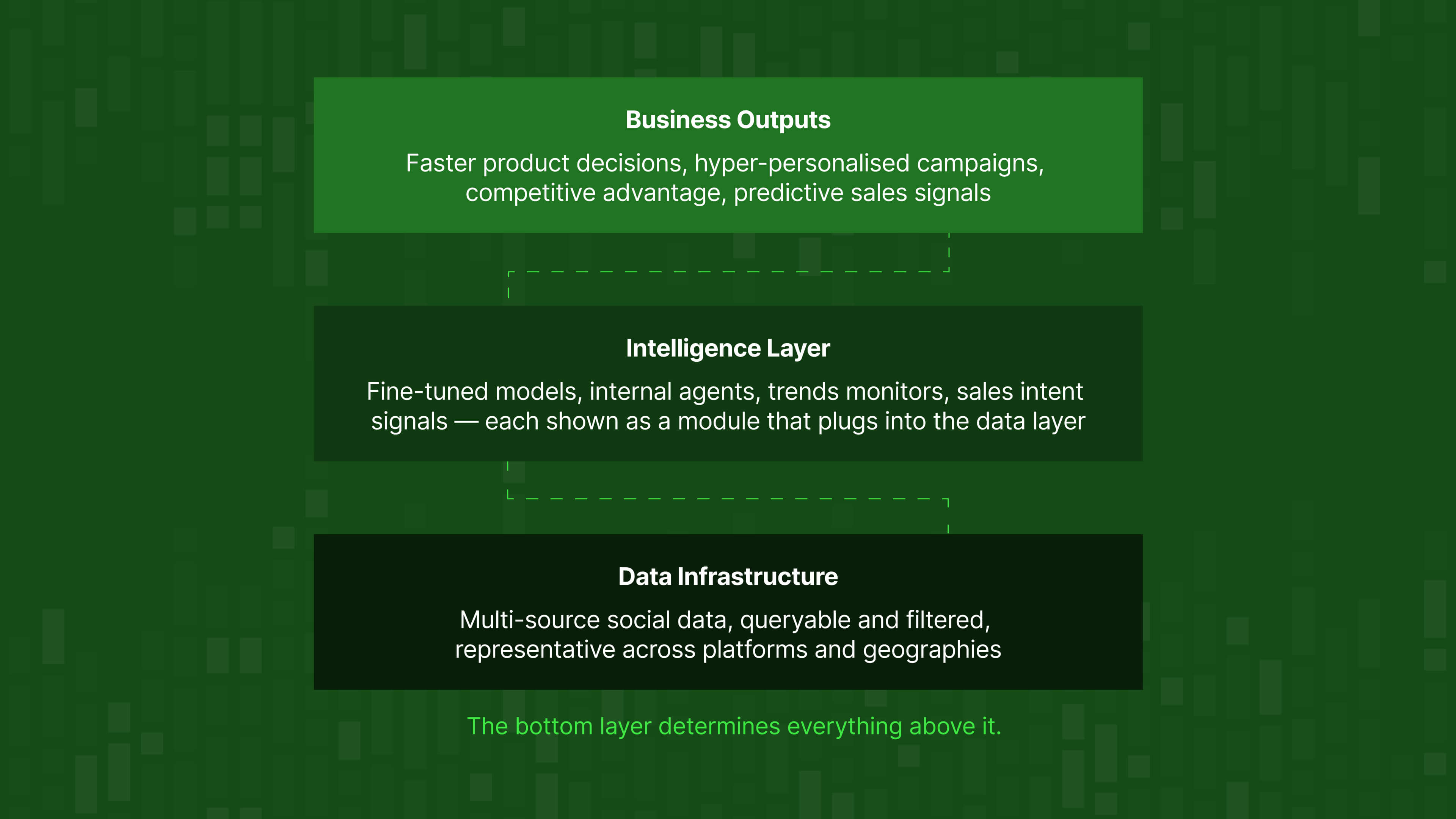
Fine-tuned models that deeply understand your market
Models trained on the open web have learned general language patterns, not the specific vocabulary, concerns, and framing of your industry or customer base.
Domain-specific fine-tuning closes that gap.
- BloombergGPT, trained on financial text, significantly outperformed general models on financial tasks.
- Med-PaLM 2 did the same for medical contexts. The pattern is consistent: a model trained on the language of your specific domain is a qualitatively different model – with measurable improvements in accuracy, relevance, and hallucination rate.
What social data enables is fine-tuning on how real people in your market actually talk about the things that matter to your business. Not how journalists covered them. Not how your marketing team framed them. How your actual customers and prospects articulate their needs, frustrations, comparisons, and decisions – in their own words, unprompted.
And importantly: the data feeding the model is human-generated, not synthetic. Which means you're actively fighting model collapse rather than accelerating it.
Internal intelligence agents your whole company can use
Enterprise AI agent infrastructure spending hit $18 billion in 2025. The vision (agents that surface intelligence, monitor signals, and trigger workflows without requiring a data scientist every time) is becoming standard infrastructure, not a research project.
But agents are only as good as the data they're grounded in. An internal reputation agent that monitors your brand's position across social conversation is useful if it draws on broad, representative, current social data. It's dangerously misleading if it draws on a single-platform API feed dominated by power users in one geography.
What good social data infrastructure makes possible:
- A brand intelligence agent that surfaces emerging sentiment shifts across the specific communities where your customers actually talk, not just the mainstream platforms your team already monitors
- A competitive intelligence agent that tracks how your competitors are being discussed in context, not just whether they're being mentioned
- A trends intelligence agent that tracks emerging language and conversations in real time, identifying what's gaining traction before it goes mainstream. Consumer interests shift constantly, and the teams that benefit most aren't the ones who react fastest; they're the ones who saw it coming. By the time a trend appears in a report or a dashboard, the window for first action is usually closing. Social data is where you catch it while it's still open.
Because the data is queryable and filterable, these agents can be configured to the specific product lines, geographies, and risk categories that matter to your business.
Predictive models calibrated to your context
The most sophisticated use case: building predictive models trained on your specific market's authentic social signal, rather than generic internet norms.
- A sales intelligence model trained on social conversations in your vertical will produce better buyer intent signals than a generic scoring model – because it's learned the language patterns that precede purchase in your specific category
- A marketing performance predictor trained on how your audience responds to specific content types (as expressed in organic social conversation) will outperform a model trained on aggregate clickthrough data
- A product intelligence model trained on customer reviews and forum threads will surface unmet needs earlier than any survey, because the data exists before anyone thought to ask the question
- A sales intelligence model trained on social conversations in your vertical will produce better buyer intent signals than a generic scoring model, because it's learned the language patterns that precede purchase in your specific category. That includes the signals most scoring models miss entirely: someone complaining about a competitor's product, someone publicly asking for recommendations, someone describing a problem your solution solves without knowing your name yet. Those are buying signals. They're hiding in plain sight on social platforms every day.
💡 Before you decide to build your own social data pipeline, read this first: Should You Build vs Buy Your Social Media Data Pipeline?
The lead-time advantage

Purchase data tells you what people bought. Social data tells you what they're thinking before they buy, or before they churn. That lead time is where the competitive advantage lives.
And the implications go well beyond training large models. Raw social data is increasingly the input that powers a new generation of B2C marketing and sales execution, not just research. The global hyper-personalisation market is projected to grow from $21.8 billion in 2024 to nearly $49.6 billion by 2029, driven by one core shift: brands that can anticipate what a customer needs before they articulate it are consistently outperforming those that can't.
Social data makes that anticipation possible at a level no other source can match. When someone publicly complains about a competitor, asks for product recommendations in a forum, or describes a problem they're trying to solve – that is a live buying intent signal, expressed spontaneously and without any research prompt. Feed that into your own models and you're not just training a better LLM. You're building a system that can identify and act on demand as it emerges, in real time: triggering personalised outreach, adjusting ad targeting, or surfacing the right offer at exactly the moment someone is most likely to convert.
Sales outreach is already shifting from broad-based approaches to signal-driven methods, using intent data and AI prioritisation to engage buyers when they're most receptive. Social data is where the cleanest, most unfiltered version of those signals lives, before they've been processed, packaged, or sold by a third party.
Getting to the right data, not just a lot of data
A practical note: having access to massive social datasets is not the same as being able to use them. Without the ability to query, filter, and extract the relevant signal, even the best data infrastructure produces an unmanageable firehose.
What good data infrastructure actually delivers:
- The ability to define exactly what you need (by topic, source, language, date range, engagement threshold) and receive a clean, filtered dataset rather than a raw dump
- Metadata-enriched output that makes downstream filtering and segmentation possible
- Provenance transparency. The ability to see, specifically, what percentage of your dataset comes from which source types, so you can assess and correct for representativeness issues before they contaminate your analysis or your model
This matters because it's not just a data problem, it's a capabilities problem. And the data is where it starts.
An imperative for control
Most of the conversation about social data focuses on what you can learn about the world. There's an equally important dimension: control over what your AI sees.
When you build AI capabilities on generic training data (open web scrapes, synthetic datasets, single-platform API feeds) you're ceding control of your model's worldview to whatever that data happens to contain. You inherit its biases, its gaps, its demographic skews, and its contamination without necessarily knowing it.
The teams building the most defensible AI capabilities have decided to take control of the input. They define which sources feed their models. They set the demographic and geographic filters. They query for relevance rather than accepting whatever comes. They audit the composition of their training data before it shapes their model's outputs.
This is a strategic decision about what your AI believes about the world, how it represents your customers, and whether its outputs can be trusted in production.
Having a provider who helps you go from raw social volume to the right data – representative, filtered, queryable, transparent in its composition – is what turns social data into a competitive advantage.
The bottom line
The open web is running out of clean, human-generated data. Survey panels are drowning in fraud. And the AI models most companies are building their capabilities on were trained on a mix of synthetic output, skewed platform data, and financially-motivated responses.
Meanwhile, every day, millions of people post, comment, review, debate, and describe their experiences across social platforms – without being asked, without being paid, and without knowing anyone is watching. That data is as close to a pure signal of human opinion as exists at scale, anywhere.
The companies that figure out how to access it properly, filter it intelligently, and use it to train and calibrate their AI (rather than relying on whatever the open web still provides) will have a meaningful and durable advantage over those that don't.
Key takeaways
- The training data crisis is here, not coming. High-quality human-generated text is being exhausted between 2026 and 2032 at current training rates. The open web is now majority AI-generated content. Model collapse (the degradation that happens when AI trains on AI) is already observable in production tools. Social data is one of the last large-scale reservoirs of structurally authentic human expression.
- The licensing deals prove the point. Google and OpenAI aren't paying $130 million a year to Reddit for brand awareness. They're paying it because authentic, at-scale human conversation is the training asset their models depend on.
- Good social data is harder to get than it looks. Platform APIs give you a permission-filtered sliver. Volume without quality and relevance filtering is a firehose, not an asset. And a dataset dominated by one platform inherits that platform's demographic skew.
- Surveys are not a substitute. Incentivised opinion is distorted opinion. The survey panel industry is discarding nearly half its data due to fraud and disengagement. Social data captures what people actually think, in their own words, before anyone asked them to think it.
- The real competitive advantage is control over the input. The teams building defensible AI capabilities aren't just accessing more data – they're deciding which data feeds their models, filtering for what's relevant, and auditing the composition of their training sets before they shape their model's worldview.
Use Datashake to source the social data for your AI training
Datashake provides social data infrastructure for teams that need more than a dashboard.
The quality and representativeness of your underlying data determines everything that comes after it.
We help you get from raw social volume to the right data: queryable, filterable, multi-source, and transparent in its composlition. 🙌



More insights you might like


