Social Data Deduplication: What It Is, How It Works, and Why Bad Dedup Breaks Your Analytics

Your social listening tool says your brand was mentioned 10,000 times last month. Before you report that number upward, ask yourself:
- How many of those were the same news story picked up by 40 regional outlets?
- How many were retweets of one original post?
- How many were AI-generated?
- How many were bots amplifying a narrative that never actually existed?
Without proper deduplication, you genuinely don't know. And that's not just a data cleanliness issue, it's a business intelligence problem. Every metric, alert, and decision built on that data is built on a number that doesn't mean what you think it means.
This guide covers what social data deduplication is, the different duplication problems in social data pipelines, how deduplication works technically, what the real-world consequences of getting it wrong look like, and how to evaluate whether the data you're working with has been properly deduplicated.
Let’s dive right in ⬇️
What is social data deduplication?
Social data deduplication is the process of identifying and removing redundant records from a dataset so that each unique post, article, or mention is counted once.
In data engineering, the goal is to produce what's called a golden record: a single authoritative version of each piece of content. Instead of the same post appearing five times across five collection windows, you get one clean, canonical record with all its metadata attached.
Everything downstream (sentiment scoring, volume trends, share of voice, topic analysis, crisis alerts) runs against that clean dataset. If the dataset isn't clean, none of those outputs are trustworthy.
The problem is that "clean" is harder to achieve in social data than in almost any other data domain.
→ Social data deduplication starts with having complete data to work with in the first place – here's why your social media data is probably more incomplete than you think.
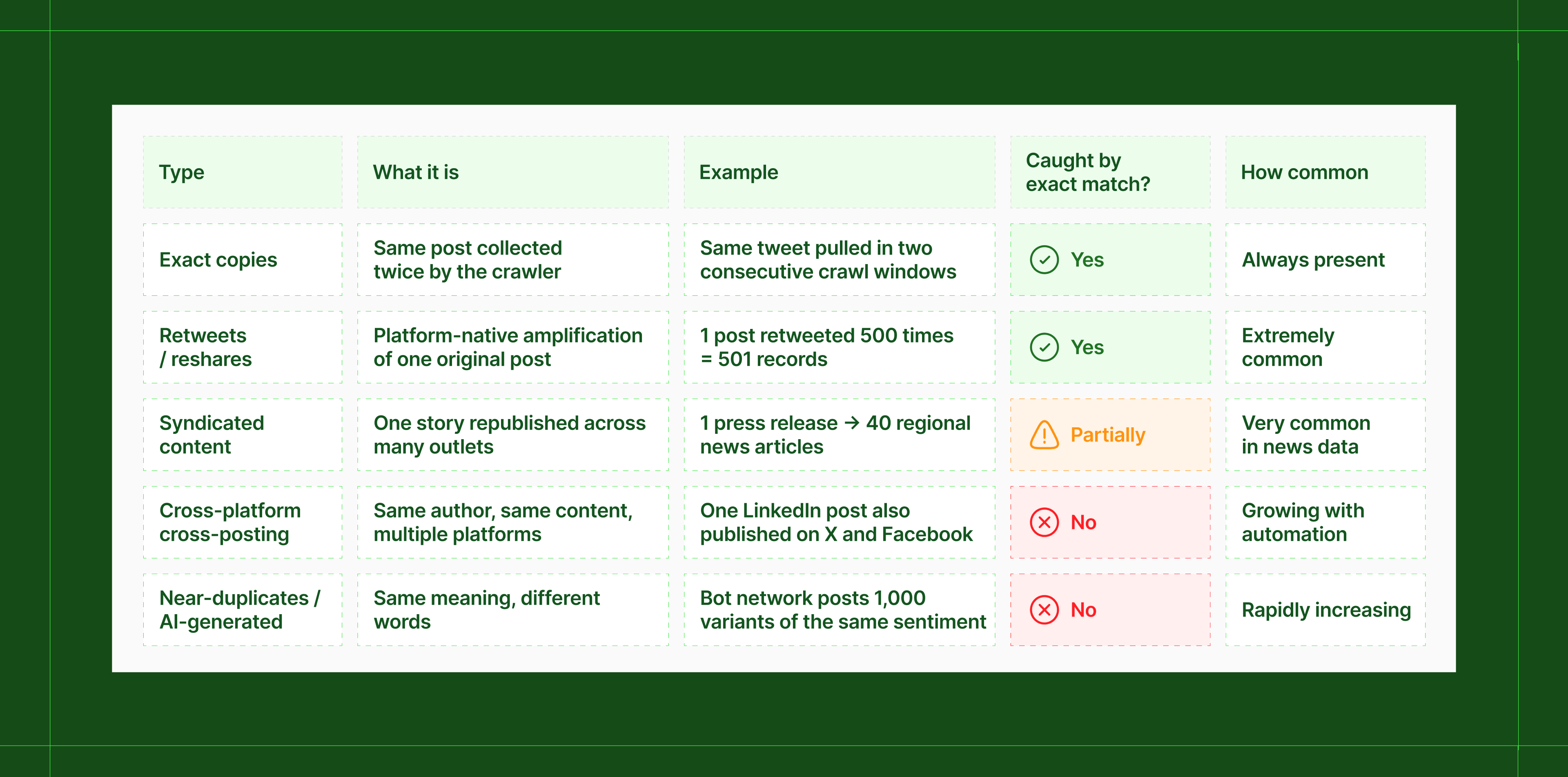
The 5 types of duplication problems in social media pipelines
Social data doesn't have one duplication problem. It has five distinct ones, and they require different solutions.
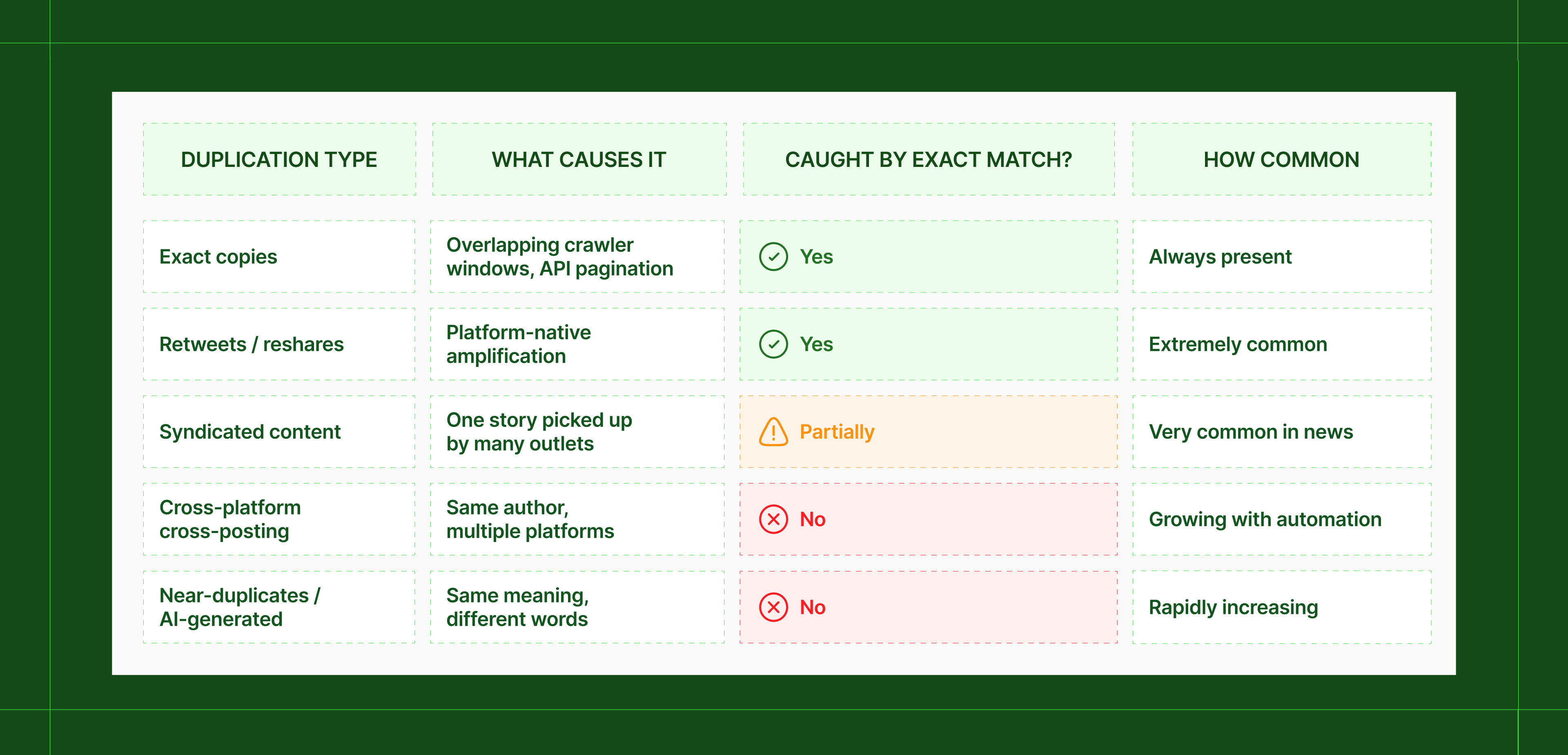
1. Exact copies
Crawlers running on overlapping schedules, or pagination logic with gaps, collect the same post twice, sometimes many more times.
These are the easiest to catch (hash the content, compare IDs, discard duplicates) but they're also the most foundational.
If you're not catching these, nothing else matters. ⚠️
2. Retweets and reshares
Resharing is built into how social platforms work. A single post can be retweeted thousands of times, each retweet generating its own record in a raw data pipeline.
The tricky part is that retweets are both signal and noise at the same time. As signal, they tell you how far a piece of content travelled: that's amplification data, and it's useful. As noise, the text is identical and each retweet counted as a unique mention inflates your volume baseline with no new information.
What good deduplication does here: stores reshares as engagement metadata on the original post rather than discarding them. The amplification is preserved; the volume inflation is not. From a data collection standpoint, retweets don't contribute new content, but they do contribute distribution data.
3. Syndicated content
A press release goes out. A major outlet covers it. Forty regional publications pick up the same story, often verbatim or with minor edits. News aggregators republish again. Each one becomes a separate record in your pipeline.
This is the duplication problem that most visibly corrupts earned media measurement and share of voice. Social listening tools should be able to deduplicate syndicated articles and separate reshares from original posts.
Sadly though, most don't do this well. One story becomes dozens of "brand mentions", and any metric built on those numbers becomes systematically wrong.
4. Cross-platform cross-posting
The same author posts the same content across multiple platform😳s simultaneously. If your pipeline pulls from all those platforms without cross-source deduplication, you count it multiple times.
This problem scales with source breadth. Pulling from 5 sources? Manageable.
Pulling from 150+? Cross-dataset deduplication – identifying the same content across sources with different schemas, different post IDs, different timestamp formats, and different definitions of what a "post" even is – is a substantially harder engineering problem than within-source deduplication.
→ "Coverage breadth directly affects how badly cross-posting inflates your numbers – use this framework to evaluate whether your data sources are actually representative.
5. Near-duplicates and AI-generated content
Two posts that say the same thing in different words won't be caught by exact-match deduplication. This has always existed with organic content (think spin-off articles, forum reposts, paraphrase bots). But AI-generated content has made it structural.
In 2025, mentions of "AI slop", the shorthand for low-quality, mass-produced AI content, increased ninefold compared to 2024.
AI-generated content now accounts for more than half of all English-language content on the web. A growing share of that ends up on social platforms as thousands of near-identical posts expressing the same manufactured sentiment in slightly different words.
Standard deduplication won't catch this. Research published at EMNLP 2024 found that existing methods relying on surface linguistic features fundamentally fail to handle semantic-level duplication prevalent in noisy social media data.
→ TikTok and Reddit have very different amplification dynamics – see how the two platforms compare for community conversation.
How deduplication works: 4 methods explained
No single technique solves all five duplication types. A robust pipeline applies multiple methods in sequence, with each layer catching what the previous one missed.
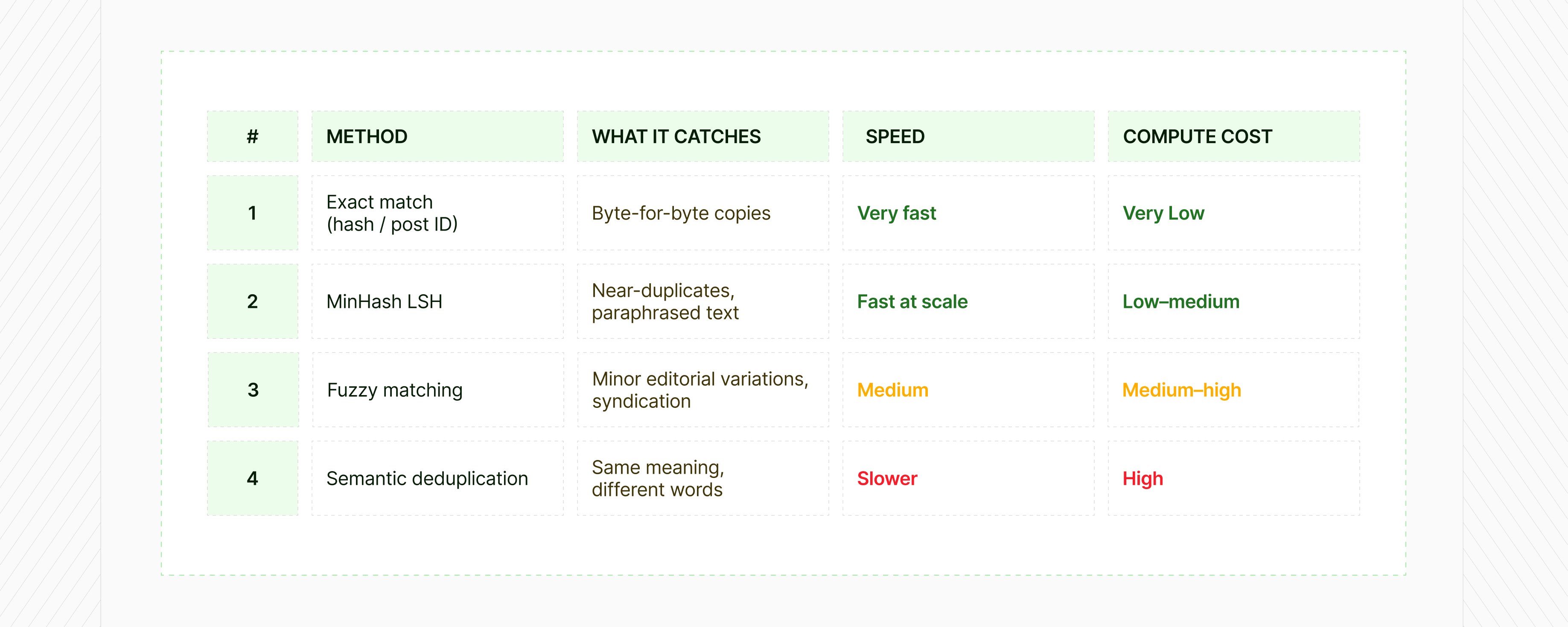
Tier 1: Exact match
Exact match deduplication works by generating a unique fingerprint (called a hash) from the raw text of each post.
Think of it like a digital DNA test: if two posts are identical, they produce the same hash value, and one gets discarded. If anything is different – even a single character, a trailing space, or a punctuation mark – the hashes diverge and both records pass through as unique.
The majority of platforms also assign native post IDs, which can be used as an additional identifier. A retweet of post ID 1234 is still post ID 1234, so ID-matching catches reshares even before hashing runs.
This tier is fast and cheap to run at scale. It's the first pass every pipeline should make. The limitation is equally simple: it only catches records that are perfectly, byte-for-byte identical.
The moment a syndicated article changes one word, or an AI-generated post varies a sentence, exact matching sees two different documents, even if they're saying exactly the same thing. That's what the next tiers are for. ⬇️
Tier 2: MinHash Locality-Sensitive Hashing
MinHash LSH is the industry standard for large-scale near-deduplication. It represents each document as a set of overlapping character sequences (shingles), generates a compact signature, and uses probabilistic bucketing to find high-similarity records without comparing every possible pair, which would be computationally impossible at scale.
It catches lightly paraphrased text, reordered content, and minor wording changes. Research on LLM training datasets found MinHash can reduce dataset size by 20–40% while improving downstream model performance by 5–15%. The deduplication removes redundancy that was actively harming the model, not just wasting space.
→ Why social data is becoming the most valuable AI training asset, and why the quality of that data determines the quality of what you build on top of it.
Tier 3: Fuzzy matching
Fuzzy deduplication uses similarity metrics – Levenshtein distance (edit distance between strings), Jaro-Winkler, phonetic matching – to identify duplicates where content is similar but not close enough for MinHash to catch.
The tradeoff is compute cost. Fuzzy matching is significantly more expensive than hashing or MinHash, which is why you don't run it on everything, you run it on the candidates that passed through earlier tiers.
Leading AI research labs use a three-stage architecture:
- Exact deduplication first (fastest, cheapest)
- MinHash second (catches most near-duplicates at scale)
- Then fuzzy matching third (handles the editorial variations the first two missed).
Running them in that order means fuzzy matching only touches a fraction of the original dataset, keeping the overall pipeline fast without sacrificing coverage.
Tier 4: Semantic deduplication
The first three tiers all work on the surface of text, comparing characters, sequences, and edit distances. Semantic deduplication works differently. It tries to understand what a post means, not just what it says.
Consider two posts: 1️⃣"This product completely changed how I work" and 2️⃣ "Game changer for my workflow, honestly". No shared words beyond function words.
- Levenshtein distance would treat them as completely different
- MinHash wouldn't flag them either.
- But they're expressing the same sentiment about the same thing, and if thousands of AI-generated variants of that idea are flooding a dataset, treating each one as a unique data point produces a badly skewed picture of what people actually think.
This is the problem semantic deduplication solves. Rather than comparing text directly, it maps each post to a compressed representation of its meaning, and groups records whose meanings converge, regardless of how differently they're worded.
Research published at EMNLP 2024 by researchers at Hong Kong Polytechnic University takes a specific approach to this: train a generative model to predict a single core keyword from the text of a social post, then treat posts that produce the same keyword as semantic duplicates.
It's a lightweight proxy for meaning – cheap enough to run at scale, but still operating at the level of what a post is actually about rather than how it's written.
This tier is computationally heavier than the others and typically reserved for datasets where AI-generated or bot-amplified near-identical content is a known problem.
Where in the pipeline does deduplication happen?
Deduplication should run at multiple stages, not just as a post-hoc cleanup:
- Pre-collection: Eliminate duplicate URLs before data is even fetched
- At ingestion: Catch exact matches and near-duplicates as records arrive
- Post-processing: Handle cross-source near-duplicates that require schema normalisation first
- Incremental: Compare new records against existing data rather than reprocessing everything; critical for continuous pipelines across many sources
Deduplication at multiple stages tends to be more effective than a single cleanup pass, and substantially cheaper in aggregate because it prevents duplication from compounding.
→ Deduplication is one of six fixes that make a meaningful difference to pipeline quality – see the full list here.
Cross-source social data deduplication: why it's harder than it looks
Deduplicating within a single source is straightforward. You have one schema, one set of post IDs, one timestamp format, one definition of what a record is. You build the logic once and it works consistently.
Cross-source deduplication across 50, 100, or 150+ sources simultaneously is a different problem.
Why the same content looks completely different across sources
Start with the most basic challenge: when data is collected from multiple web sources, duplication and inconsistency are almost guaranteed. ⬇️
- The same piece of content arrives from different sources looking completely different
- A post ID that uniquely identifies a record on one platform means nothing on another – platforms generate their own IDs independently, so two different IDs can refer to the exact same piece of content.
- Timestamps diverge based on how each source records them
- Field names differ. One source calls it post_text, another calls it content, another calls it body
- And what counts as a "post" versus a "comment" versus a "reply" is defined differently by each platform – so the same record type gets classified differently depending on where it came from.
Schema normalisation: the step that has to come first
None of this is solvable by deduplication logic alone. Before you can compare records across sources, you need to make them comparable – and that means schema normalisation: transforming heterogeneous data from dozens of different sources into a single unified structure where fields mean the same things, IDs are mapped to a canonical reference, timestamps are standardised, and content types are classified consistently.
Schema normalisation is its own engineering project, separate from and prior to deduplication. You're essentially solving two hard problems in sequence: first make the data comparable, then find the duplicates within the now-comparable dataset.
What this means at production scale
Then add the scale constraint. Cross-dataset deduplication must handle distinct schemas, tokenisations, and normalisation forms; structural noise and sparse fields; and massive volume within production service-level constraints – all in real time, continuously, as new data arrives from all 150+ sources simultaneously.
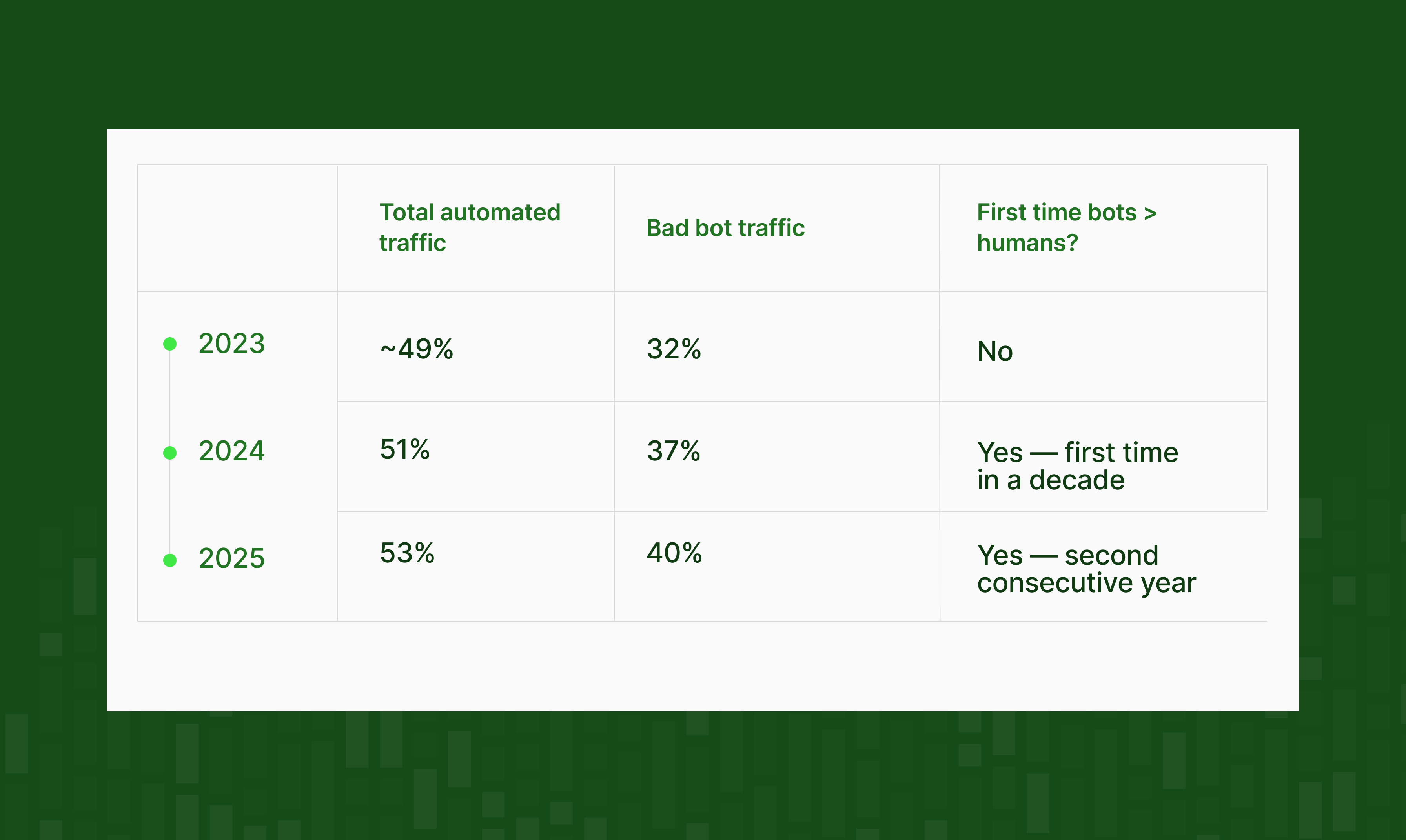
Why bot traffic and AI content are making social data deduplication harder
According to Imperva's 2025 Bad Bot Report, automated traffic surpassed human activity for the first time in a decade in 2024, accounting for 51% of all web traffic.
By 2025, that figure had climbed to 53%, the second consecutive year bots have outnumbered humans online.
Bad bots specifically (the kind engineered to amplify narratives, scrape content, generate spam, and commit fraud) now account for 40% of all internet traffic, a figure that has risen for seven consecutive years.
Bots don't just live on the open web, they live on social platforms
Social bots make up around 5% of accounts on X, but generate nearly 30% of its content. That's a 6x amplification ratio; a small number of automated accounts producing a disproportionate share of what appears to be conversation.
This has a direct consequence for anyone collecting social data at scale: a meaningful proportion of every raw dataset is not human-generated content. It's automated posts, coordinated amplification, and AI-generated text engineered to look organic.
Social media data collection has historically assumed it was capturing human communication. That assumption is no longer valid without active deduplication and bot filtering built into the pipeline.
What goes wrong when deduplication fails
Here's what bad deduplication costs ⬇️
Inflated volume metrics corrupt every benchmark
If your mention baseline is inflated by retweets, syndicated articles, and bot posts, every comparison against that baseline is wrong.
⚠️ "We saw a 40% spike this week" might mean genuine conversation growth, or it might mean one story went to wire services. You can't tell the difference without deduplication.
Share of voice becomes a measure of content distribution, not conversation
Share of voice is a ratio: your mentions versus the total.
If a competitor's one story was syndicated across 200 outlets and yours appeared in 20, their SOV looks dramatically higher – not because more people are talking about them organically, but because of syndication infrastructure. You're measuring content distribution instead of market presence.
Sentiment scoring misfires
A single critical post retweeted 500 times, treated as 500 negative mentions, produces a sentiment crash on your dashboard for that day, even if organic conversation is entirely neutral.
This is the mechanism behind a large proportion of false crisis alerts. Teams scramble to respond to something that didn't actually represent widespread opinion.
Real decisions get made on phantom data – the Cracker Barrel case
In 2024, Cracker Barrel announced a brand refresh.
Within two weeks, more than 2 million posts appeared on X about it. T
he backlash appeared enormous. The company reversed the decision. But a report by PeakMetrics found that 44% of a sample of 52,000 X posts in the first 24 hours were flagged as likely coming from bot accounts. The apparent consumer sentiment that drove the reversal was nearly half synthetic.
That's what deduplication failure at scale looks like: a business decision made in response to manufactured signals.
AI features trained on duplicated data inherit the bias
If your product trains any kind of NLP model, sentiment classifier, or AI feature on social data – and that training data wasn't deduplicated – the model learns from a skewed corpus.
Research has shown that social media datasets suffer from severe redundancy, and that training on deduplicated data consistently outperforms training on raw data, and does so faster. Duplicate records don't just waste compute; they over-represent certain content types and bias the model accordingly.
Before integrating any social data API, run through this evaluation first, a practical guide to what to check before you integrate.
What does good social data deduplication look like? A checklist for evaluating your pipeline
Done properly, deduplication gives you three things that you can't get otherwise:
1. True unique post counts. You know how many distinct pieces of content mention your brand or topic, not how many times the same content was shared or republished. That's the number decisions should be built on.
2. Separate signals for reach and breadth. "How many unique people said this?" and "how far did it travel?" become two different, answerable questions. The first tells you about genuine conversation breadth. The second tells you about amplification. Both matter, but conflating them is how analytics breaks.
3. Reliable input for everything downstream. Sentiment models, topic models, trend detection, anomaly alerts – all of these work better when inputs aren't riddled with copies. This is consistent across contexts: research has shown that deduplication improves NLP model performance while reducing training time.
Questions to ask when evaluating a social data provider
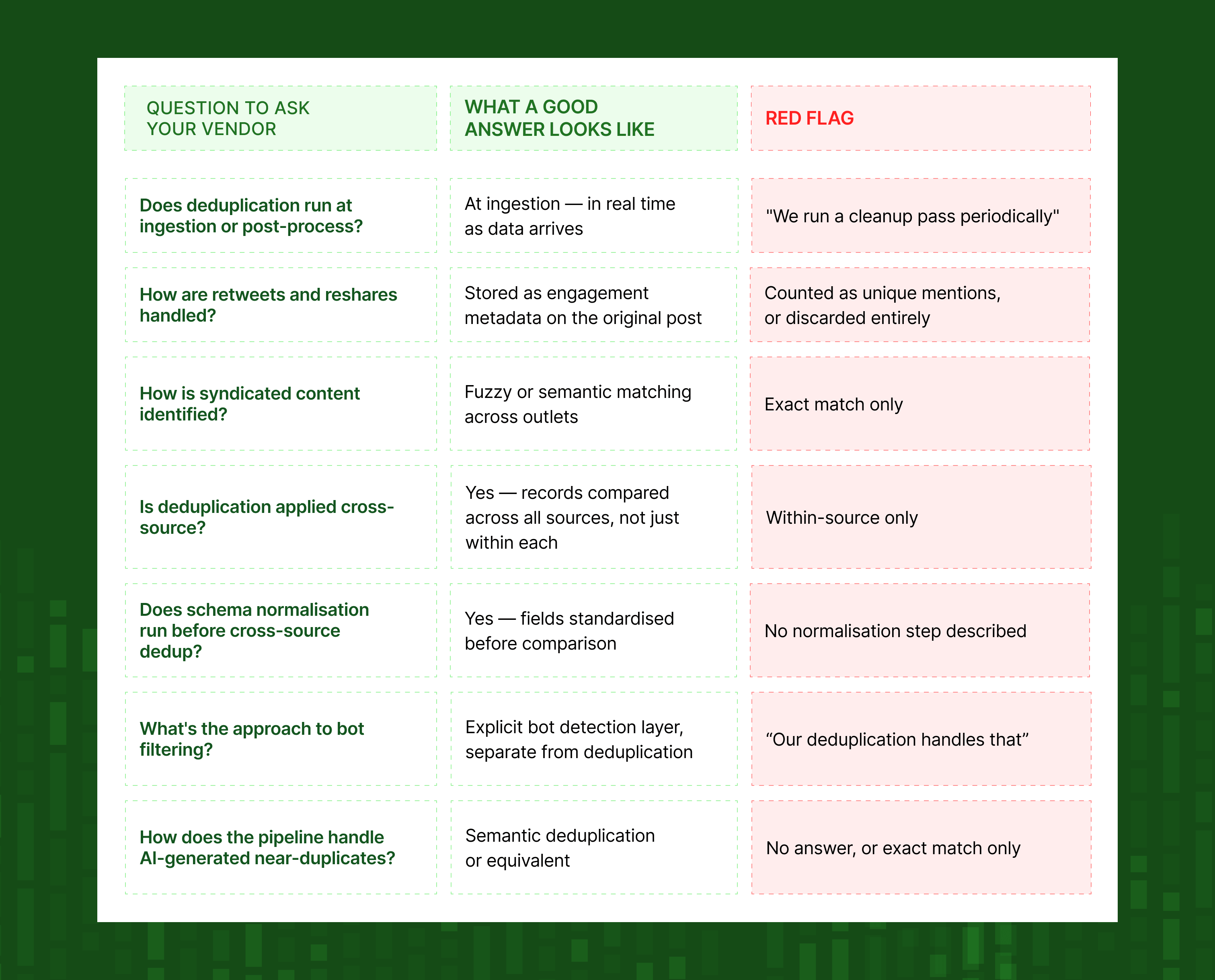
If you're building on third-party social data, or evaluating whether to switch providers, these are the questions to ask:
- Does the pipeline deduplicate at ingestion, or only as a post-process? Post-process deduplication is slower and misses duplicates that affect real-time use cases.
- How are retweets and reshares handled? Are they discarded, treated as unique posts, or stored as engagement metadata on the original? The right answer is the third one.
- How is syndicated content identified and collapsed? What's the method – exact match, fuzzy, semantic? How does it handle minor editorial variations?
- Is deduplication applied cross-source? If you're pulling from multiple platforms, are records compared against each other across sources, or only within sources?
- Is there schema normalisation before cross-source deduplication runs? Without normalisation, cross-source comparison isn't meaningful.
- What's the approach to bot filtering? Deduplication and bot filtering are related but distinct. Both are necessary.
- How does the pipeline handle the near-duplicate / AI-generated content problem? If the answer doesn't include semantic deduplication or something equivalent, it doesn't fully address the current landscape.
Data quality is the unsolved problem
Data quality is the biggest obstacle to social intelligence delivering real value ⬇️
- Forrester found that more than one quarter of data and analytics professionals estimate their organisations lose over $5 million annually to poor data quality, and that was before AI entered data pipelines at scale.
- The Social Intelligence Lab's State of Social Listening 2025 found data access and quality remain the top obstacles, even as investment in social listening increases.
- Forrester has also specifically called out bad data gathering and unreliable reporting as the primary reasons social listening initiatives fail to deliver.
- The 2023 State of Social Listening report put data accuracy and quality as the top challenge for 44.6% of in-house practitioners – above budget constraints, above tool complexity, above everything else.
But the answer to bad data isn't more data. Collecting more of the wrong thing makes the problem worse. Deduplication is fundamentally about knowing what your dataset actually represents, not just how large it is.
Summary: what you need to know at a glance
The bottom line
Social data deduplication is not a feature you add later. It's the foundation that every metric, every alert, every model, and every downstream decision depends on.
If your pipeline doesn't deduplicate – and deduplicate well, across sources, in real time, with semantic awareness – you're not measuring conversation. You're measuring a combination of genuine conversation, bot noise, content syndication infrastructure, and whatever the internet's amplification machinery decided to do with one post on a given day.
For social intelligence platforms, reputation management tools, CX products, and any SaaS team embedding third-party social or review data: the quality of deduplication in your data layer determines the quality of every insight your product produces. A great model trained on a dirty dataset produces confidently wrong outputs. ❌ A great dashboard built on inflated metrics erodes trust with every misleading spike. ❌
Datashake aggregates social and review data from 150+ sources via a single, normalised API. We handle deduplication at the infrastructure layer, so your team works with clean, comparable data from day one.



More insights you might like


